架构设计:生产者-消费者模式[3]:环形缓冲区
架构设计:生产者/消费者模式[3]:环形缓冲区
前一个帖子 提及了队列缓冲区可能存在的性能问题及解决方法:环形缓冲区。今天就专门来描述一下这个话题。
为了防止有人给咱扣上“过度设计”的大帽子,事先声明一下:只有当存储空间的分配/释放非常【频繁】并且确实产生了【明显】的影响,你才应该考虑环形缓冲区的使用。否则的话,还是老老实实用最基本、最简单的 队列缓冲区 吧。还有一点需要说明一下:本文所提及的“存储空间”,不仅包括内存,还可能包括诸如硬盘之类的存储介质。
在介绍环形缓冲区之前,咱们先来回顾一下普通的队列。普通的队列有一个写入端和一个读出端。队列为空的时候,读出端无法读取数据;当队列满(达到最大尺寸)时,写入端无法写入数据。
对于使用者来讲,环形缓冲区和队列缓冲区是一样的。它也有一个写入端(用于 push)和一个读出端(用于 pop),也有缓冲区“满”和“空”的状态。所以,从队列缓冲区切换到环形缓冲区,对于使用者来说能比较平滑地过渡。
虽然两者的对外接口差不多,但是内部结构和运作机制有很大差别。队列的内部结构此处就不多啰嗦了。重点介绍一下环形缓冲区的内部结构。
大伙儿可以把环形缓冲区的读出端(以下简称 R)和写入端(以下简称 W)想象成是两个人在体育场跑道上追逐。当 R 追上 W 的时候,就是缓冲区为空;当 W 追上 R 的时候(W 比 R 多跑一圈),就是缓冲区满。
为了形象起见,去找来一张图并略作修改,如下:
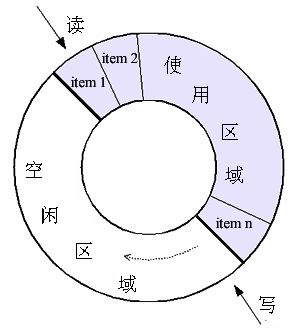
从上图可以看出,环形缓冲区所有的 push/pop 操作都是在一个【固定】的存储空间内进行。而队列缓冲区在 push 的时候,可能会分配存储空间用于存储新元素;在 pop 时,可能会释放废弃元素的存储空间。所以环形方式相比队列方式,少掉了对于缓冲区元素所用存储空间的分配、释放。这是环形缓冲区的一个主要优势。
如果你手头已经有现成的环形缓冲区可供使用,并且你对环形缓冲区的内部实现不感兴趣,可以跳过这段。
环形缓冲区的内部实现,即可基于数组(此处的数组,泛指连续存储空间)实现,也可基于链表实现。
数组在物理存储上是一维的连续线性结构,可以在初始化时,把存储空间【一次性】分配好,这是数组方式的优点。但是要使用数组来模拟环,你必须在逻辑上把数组的头和尾相连。在顺序遍历数组时,对尾部元素(最后一个元素)要作一下特殊处理。访问尾部元素的下一个元素时,要重新回到头部元素(第0个元素)。如下图所示:

使用链表的方式,正好和数组相反:链表省去了头尾相连的特殊处理。但是链表在初始化的时候比较繁琐,而且在有些场合(比如后面提到的跨进程的 IPC)不太方便使用。
环形缓冲区要维护两个索引,分别对应写入端(W)和读取端(R)。写入(push)的时候,先确保环没满,然后把数据复制到 W 所对应的元素,最后 W 指向下一个元素;读取(pop)的时候,先确保环没空,然后返回 R 对应的元素,最后 R 指向下一个元素。
上述的操作并不复杂,不过有一个小小的麻烦:空环和满环的时候,R 和 W 都指向同一个位置!这样就无法判断到底是“空”还是“满”。大体上有两种方法可以解决该问题。
办法1:始终保持一个元素不用
当空环的时候,R 和 W 重叠。当 W 比 R 跑得快,追到距离 R 还有一个元素间隔的时候,就认为环已经满。当环内元素占用的存储空间较大的时候,这种办法显得很土(浪费空间)。
办法2:维护额外变量
如果不喜欢上述办法,还可以采用额外的变量来解决。比如可以用一个整数记录当前环中已经保存的元素个数(该整数>=0)。当 R 和 W 重叠的时候,通过该变量就可以知道是“空”还是“满”。
由于环形缓冲区本身就是要降低存储空间分配的开销,因此缓冲区中元素的类型要选好。尽量存储【值类型】的数据,而不要存储【指针(引用)类型】的数据。因为指针类型的数据又会引起存储空间(比如堆内存)的分配和释放,使得环形缓冲区的效果大打折扣。
刚才介绍了环形缓冲区内部的实现机制。按照 前一个帖子 的惯例,我们来介绍一下在线程和进程方式下的使用。
如果你所使用的编程语言和开发库中带有现成的、 成熟的 环形缓冲区,强烈建议使用现成的库,不要重新制造轮子;确实找不到现成的,才考虑自己实现。(如果你纯粹是业余时间练练手,那另当别论)
和线程中的队列缓冲区类似,线程中的环形缓冲区也要考虑线程安全的问题。除非你使用的环形缓冲区的库已经帮你实现了线程安全,否则你还是得自己动手搞定。线程方式下的环形缓冲区用得比较多,相关的网上资料也多,下面就大致介绍几个。
对于 C++ 的程序员,强烈推荐使用 boost 提供的 circular_buffer 模板,该模板最开始是在 boost 1.35版本中引入的。鉴于 boost 在 C++ 社区中的地位,大伙儿应该可以放心使用该模板。
对于 C 程序员,可以去看看开源项目 circbuf ,不过该项目是 GPL 协议的(可能有人会觉得不爽);而且活跃度不太高;而且只有一个开发人员。大伙儿慎用!建议只拿它当参考。
对于 C# 程序员,可以参考 CodeProject 上的一个示例 。
进程间的环形缓冲区,似乎少有现成的库可用。大伙儿只好自己动手、丰衣足食了。
适合进行环形缓冲的 IPC 类型,常见的有“ 共享内存 和文件”。在这两种方式上进行环形缓冲,通常都采用数组的方式实现。程序事先分配好一个固定长度的存储空间,然后具体的读写操作、判断“空”和“满”、元素存储等细节就可参照前面所说的来进行。
共享内存方式的性能很好,适用于数据流量很大的场景。但是有些语言(比如 Java)对于共享内存不支持。因此,该方式在多语言协同开发的系统中,会有一定的局限性。
而文件方式在编程语言方面支持很好,几乎所有编程语言都支持操作文件。但它可能会受限于磁盘读写(Disk I/O)的性能。所以文件方式不太适合于快速数据传输;但是对于某些“ 数据单元 ”很大的场合,文件方式是值得考虑的。
对于进程间的环形缓冲区,同样要考虑好进程间的同步、互斥等问题,限于篇幅,此处就不细说了。
下一个帖子,咱们来聊一下 双缓冲区的使用 。
回到本系列的目录
为了防止有人给咱扣上“过度设计”的大帽子,事先声明一下:只有当存储空间的分配/释放非常【频繁】并且确实产生了【明显】的影响,你才应该考虑环形缓冲区的使用。否则的话,还是老老实实用最基本、最简单的 队列缓冲区 吧。还有一点需要说明一下:本文所提及的“存储空间”,不仅包括内存,还可能包括诸如硬盘之类的存储介质。
★环形缓冲区 vs 队列缓冲区
◇外部接口相似
在介绍环形缓冲区之前,咱们先来回顾一下普通的队列。普通的队列有一个写入端和一个读出端。队列为空的时候,读出端无法读取数据;当队列满(达到最大尺寸)时,写入端无法写入数据。
对于使用者来讲,环形缓冲区和队列缓冲区是一样的。它也有一个写入端(用于 push)和一个读出端(用于 pop),也有缓冲区“满”和“空”的状态。所以,从队列缓冲区切换到环形缓冲区,对于使用者来说能比较平滑地过渡。
◇内部结构迥异
虽然两者的对外接口差不多,但是内部结构和运作机制有很大差别。队列的内部结构此处就不多啰嗦了。重点介绍一下环形缓冲区的内部结构。
大伙儿可以把环形缓冲区的读出端(以下简称 R)和写入端(以下简称 W)想象成是两个人在体育场跑道上追逐。当 R 追上 W 的时候,就是缓冲区为空;当 W 追上 R 的时候(W 比 R 多跑一圈),就是缓冲区满。
为了形象起见,去找来一张图并略作修改,如下:
从上图可以看出,环形缓冲区所有的 push/pop 操作都是在一个【固定】的存储空间内进行。而队列缓冲区在 push 的时候,可能会分配存储空间用于存储新元素;在 pop 时,可能会释放废弃元素的存储空间。所以环形方式相比队列方式,少掉了对于缓冲区元素所用存储空间的分配、释放。这是环形缓冲区的一个主要优势。
★环形缓冲区的实现
如果你手头已经有现成的环形缓冲区可供使用,并且你对环形缓冲区的内部实现不感兴趣,可以跳过这段。
◇数组方式 vs 链表方式
环形缓冲区的内部实现,即可基于数组(此处的数组,泛指连续存储空间)实现,也可基于链表实现。
数组在物理存储上是一维的连续线性结构,可以在初始化时,把存储空间【一次性】分配好,这是数组方式的优点。但是要使用数组来模拟环,你必须在逻辑上把数组的头和尾相连。在顺序遍历数组时,对尾部元素(最后一个元素)要作一下特殊处理。访问尾部元素的下一个元素时,要重新回到头部元素(第0个元素)。如下图所示:
使用链表的方式,正好和数组相反:链表省去了头尾相连的特殊处理。但是链表在初始化的时候比较繁琐,而且在有些场合(比如后面提到的跨进程的 IPC)不太方便使用。
◇读写操作
环形缓冲区要维护两个索引,分别对应写入端(W)和读取端(R)。写入(push)的时候,先确保环没满,然后把数据复制到 W 所对应的元素,最后 W 指向下一个元素;读取(pop)的时候,先确保环没空,然后返回 R 对应的元素,最后 R 指向下一个元素。
◇判断“空”和“满”
上述的操作并不复杂,不过有一个小小的麻烦:空环和满环的时候,R 和 W 都指向同一个位置!这样就无法判断到底是“空”还是“满”。大体上有两种方法可以解决该问题。
办法1:始终保持一个元素不用
当空环的时候,R 和 W 重叠。当 W 比 R 跑得快,追到距离 R 还有一个元素间隔的时候,就认为环已经满。当环内元素占用的存储空间较大的时候,这种办法显得很土(浪费空间)。
办法2:维护额外变量
如果不喜欢上述办法,还可以采用额外的变量来解决。比如可以用一个整数记录当前环中已经保存的元素个数(该整数>=0)。当 R 和 W 重叠的时候,通过该变量就可以知道是“空”还是“满”。
◇元素的存储
由于环形缓冲区本身就是要降低存储空间分配的开销,因此缓冲区中元素的类型要选好。尽量存储【值类型】的数据,而不要存储【指针(引用)类型】的数据。因为指针类型的数据又会引起存储空间(比如堆内存)的分配和释放,使得环形缓冲区的效果大打折扣。
★应用场合
刚才介绍了环形缓冲区内部的实现机制。按照 前一个帖子 的惯例,我们来介绍一下在线程和进程方式下的使用。
如果你所使用的编程语言和开发库中带有现成的、 成熟的 环形缓冲区,强烈建议使用现成的库,不要重新制造轮子;确实找不到现成的,才考虑自己实现。(如果你纯粹是业余时间练练手,那另当别论)
◇用于并发线程
和线程中的队列缓冲区类似,线程中的环形缓冲区也要考虑线程安全的问题。除非你使用的环形缓冲区的库已经帮你实现了线程安全,否则你还是得自己动手搞定。线程方式下的环形缓冲区用得比较多,相关的网上资料也多,下面就大致介绍几个。
对于 C++ 的程序员,强烈推荐使用 boost 提供的 circular_buffer 模板,该模板最开始是在 boost 1.35版本中引入的。鉴于 boost 在 C++ 社区中的地位,大伙儿应该可以放心使用该模板。
对于 C 程序员,可以去看看开源项目 circbuf ,不过该项目是 GPL 协议的(可能有人会觉得不爽);而且活跃度不太高;而且只有一个开发人员。大伙儿慎用!建议只拿它当参考。
对于 C# 程序员,可以参考 CodeProject 上的一个示例 。
◇用于并发进程
进程间的环形缓冲区,似乎少有现成的库可用。大伙儿只好自己动手、丰衣足食了。
适合进行环形缓冲的 IPC 类型,常见的有“ 共享内存 和文件”。在这两种方式上进行环形缓冲,通常都采用数组的方式实现。程序事先分配好一个固定长度的存储空间,然后具体的读写操作、判断“空”和“满”、元素存储等细节就可参照前面所说的来进行。
共享内存方式的性能很好,适用于数据流量很大的场景。但是有些语言(比如 Java)对于共享内存不支持。因此,该方式在多语言协同开发的系统中,会有一定的局限性。
而文件方式在编程语言方面支持很好,几乎所有编程语言都支持操作文件。但它可能会受限于磁盘读写(Disk I/O)的性能。所以文件方式不太适合于快速数据传输;但是对于某些“ 数据单元 ”很大的场合,文件方式是值得考虑的。
对于进程间的环形缓冲区,同样要考虑好进程间的同步、互斥等问题,限于篇幅,此处就不细说了。
下一个帖子,咱们来聊一下 双缓冲区的使用 。
回到本系列的目录
版权声明
本博客所有的原创文章,作者皆保留版权。转载必须包含本声明,保持本文完整,并以超链接形式注明作者 编程随想 和本文原始地址:
https://program-think.blogspot.com/2009/04/producer-consumer-pattern-3-circle.html
本博客所有的原创文章,作者皆保留版权。转载必须包含本声明,保持本文完整,并以超链接形式注明作者 编程随想 和本文原始地址:
https://program-think.blogspot.com/2009/04/producer-consumer-pattern-3-circle.html
文章版权归原作者所有。
