数据解码 | 社运研究中的数据陷阱
数据解码 | 社运研究中的数据陷阱
#社会运动

一份《纽约时报》撑起社运研究大半边天
学者们是怎么研究社会运动的?和记者一样站在社运最前线?其实,除了少数做田野调查或是行动研究的学者,大部分社会运动的研究者都是埋在历史材料中完成作品的。社会运动风起云涌,但大多数学者并不在现场,他们做的是历史上的抗议研究。
那么,这么多二手数据哪里来呢?19世纪末,欧美政府迫于工人运动的压力,开始记录罢工的数据,这也成为了最早的社会运动数据。20世纪上半叶,社会运动的数据只限于官方对工人运动的记录,普通研究者很少诉诸第三方的数据。
这种情况到了1960年代有所改变。民权运动兴起,各类抗议涌现,形式也远远超越普通的行业罢工。而彼时的政治学研究,正经历行为主义范式的鼎盛期,各种跨国民意调查、大规模比较分析方兴未艾。政治学的调查对象,也从过去相对静态的政治制度,聚焦到团体和个人多变的政治行为。在抗议这一重要的政治行为上,研究者发现政府发布的数据已经远远不够,也终于开始考虑其他数据来源。
当时最常见的参考源,是美国和西欧报纸有关抗议的报道,其中又以纽约时报的索引数据(New York Times Index)最为著名。比如麦亚当著名的黑人民权运动研究就基于纽约时报数据,扭转了“媒体报道激发抗议” 的因果方向。蒂利的好多历史社会学研究,也是基于对欧洲各国报纸的分析。
但是,即使是如雷贯耳的名家,在他们开展研究的时代,可获取的二手数据总量还是很少,传媒报道占据了相当大的比例。不夸张地说,社运研究中的几个理论转折点,比如资源动员、政治机会结构、政治过程、新社会运动研究的开展,以及这几种思潮的相互交锋,如果没有报纸数据,绝对寸步难行。上世纪中叶的几十年,一份《纽约时报》几乎撑起了社运甚至部分历史研究的大半边天。
用今天的眼光看,信息匮乏年代产出的不少社会运动作品虽然发人深省,但其数据来源单一,也许并不能准确反映社会变迁的逻辑。
换汤不换药的“大数据”
也许是出于路径依赖,也许真的是没有好的替代方案,社运研究对于报纸索引数据的依赖,一直延续到最近二十年。麦亚当等人在斯坦福大学推出的开放数据库Dynamics of Collective Action、纽约州立大学The Cross-National Time-Series Data Archive中关于抗议的部分,依然基于《纽约时报》这一份报纸的报道。
从2013年开始,媒体和学界高度关注依托于大数据的全球整合新闻数据库(GDELT),一时间,似乎所有人都蜂拥而上试图挖掘出点新鲜玩意儿。GDELT不再依赖于单一的数据源,而是综合了一百多种语言的信息,记录了1979年至今全球各个角落发生的事件。不过,虽然原始数据量惊人,且已经到了一日一更新的程度,但其编码方式却依然换汤不换药:依照媒体报道形成事件列表。而且由于机器识别的原因,每日自动生成的原始数据分类混乱,质量远不如之前人工筛查的数据库。
有学者在十几年前就提出,除了媒介报道外,要综合非正式的网络数据进行分析(Almeida & Lichbach, 2003)。但是直到今天,在线数据由于规模太大,一般只用于个案和小样本比较分析。
对这种基于媒体报道的抗议事件分析,学界有个专门的命名叫Protest event analysis(PEA)。目前对PEA的批评很多,大致可以分成三种:一是报道选择偏差问题,即一些抗议没有得到传媒关注;二是索引选择偏差问题,即一个事件涉及社运,但没有被索引纳入;三是报道内容偏差问题,即传媒未能准确报道抗议。
在这三个问题中,第一个问题最为普遍。根据社会学家厄尔等人的整理,在选择偏差方面,事件本身的形态、新闻机构的性质和抗议话题的性质,都会影响到一个事件被传媒报道的概率。一个事件靠近新闻机构所在地,对峙中出现暴力升级,警察和反抗议团体介入,社运团体赞助运动,甚至使用扩音装置,都会提升其被报道的机会。当然,更常见的所谓“新闻性”、机构的价值观和内部制度,一地传媒业的发达程度,都是影响报道的重要因素。大部分学者估计后认为,媒体报道的抗议数量,只占真实发生事件数量的不到一半。
这还只是分析同一个国家时出现的问题。如果学者超越国界,根据报纸数据分析全球的抗议潮流,原始数据造成的偏倚则更为严重。瑞士的研究者曾经做过一项统计,他们选择了拉美三个国家墨西哥、巴拉圭、阿根廷某一年的抗议报道,发现出现在本地传媒的抗议事件,平均仅有5%得到了国际传媒的关注。最低的巴拉圭因为在世界体系中没什么存在感,更是只有可怜的1%(Herkenrath & Knoll, 2011)。
即使数据库尝试纳入多语种传媒报道,纠偏作用也微乎其微。一方面,英语媒介的报道依然是绝对主力;另一方面,传媒也没有对其他国家一视同仁,一些国家比另一些国家得到了更多的抗议报道。然而,利用这些数据库所做出的研究成果,很多都发表在各个社科领域顶尖的期刊上,包括《美国社会学评论》、《美国政治学评论》、《社会力量》等。
抗议频率还是抗议人数
除了眼球效应,传媒偏见和政治审查等的干扰,更外一个问题同样严重:在目前几乎所有的抗议数据编码方式中,一场一百人参与的集会和一百万人的革命,只是两篇重量相当的报道而已,抗议人数造成的规模差异被大大弱化了。当然,有人会反驳说,规模大的抗议一定比小的抗议得到更多的媒体关注,所以其报道数量一定也更多。没错,但是想象一下,一场百人抗议在数据库中有一条记录,但百万人的抗议充其量也就几十篇报道,但这两者间真正的规模差异和深远影响,显然远不止几十倍。
抗议人数政治的重要性毋庸赘言。各个利益团体、官方、民间和传媒就同一个示威公布的总人数,经常有好几倍的出入,足以说明抗议人数是政治正当性博弈的关键,是集体行动彰显政治实力的标志。蒂利就曾经说过,政治抗议的威力主要看其包含了多少“人类的能量”。
然而,学者们虽然普遍承认人数和规模的重要性,他们的实际研究方法与理念却存在出入。根据牛津大学社会学系学者比格斯最新的统计,自2000年起,北美顶尖的七本社会学期刊共发表了近四十篇利用事件数据写成的社运论文。学者们在描绘历史上抗议的涨落时,往往将数据编码为“哪一段时间内发生了多少次抗议”,而不是“一次抗议持续多久,有多少人参与”。也就是说,抗议的规模,在研究的操作化中被偷换了概念。
单方面比较抗议数量是不少研究者图省事的结果。因为很多数据库对抗议的定义并未做细分,导致其涉及到多种抗争主体,农民抗争、工人罢工、种族暴力、城市骚乱等。同时,数据也往往包含截然不同的抗议形式,比如示威、罢工、抵制、情愿等,有部分噪点较高的数据,甚至把户外演唱会等非政治活动都计算了进去。显然,一次农村请愿的人数和一次城市集会的人数,一个参与抵制的消费者和一个当街自焚的异议者,用数量来把他们作比较同样显得简单粗暴。很多研究者面对此情形,索性就把所有的抗议揉在一起,仅计算抗议的频率。
那么,单纯比较抗议数量,会造成多大的偏差呢?这可以间接通过比较抗议数量和抗议人数的相互关系和内部差异得知。为了消除不同抗争形式无法比较的问题,比格斯将四个不同数据库中的各种抗议做了分类统计。果然,至少在美国,几十年来抗议数量与抗议人数间的相关性极其微弱。如果单看示威的数量(图中红色虚线),峰值出现在六十年代中,然后在七十年代初时跌入谷底。而示威人数(图中蓝色实线)反映出的现实则是,抗议者数量的高峰正出现在抗议数量呈现低谷期的八十年代初。整个八九十年代,示威参与人数都有极大的波动,但在抗议事件数量上,则呈现四平八稳的格局。
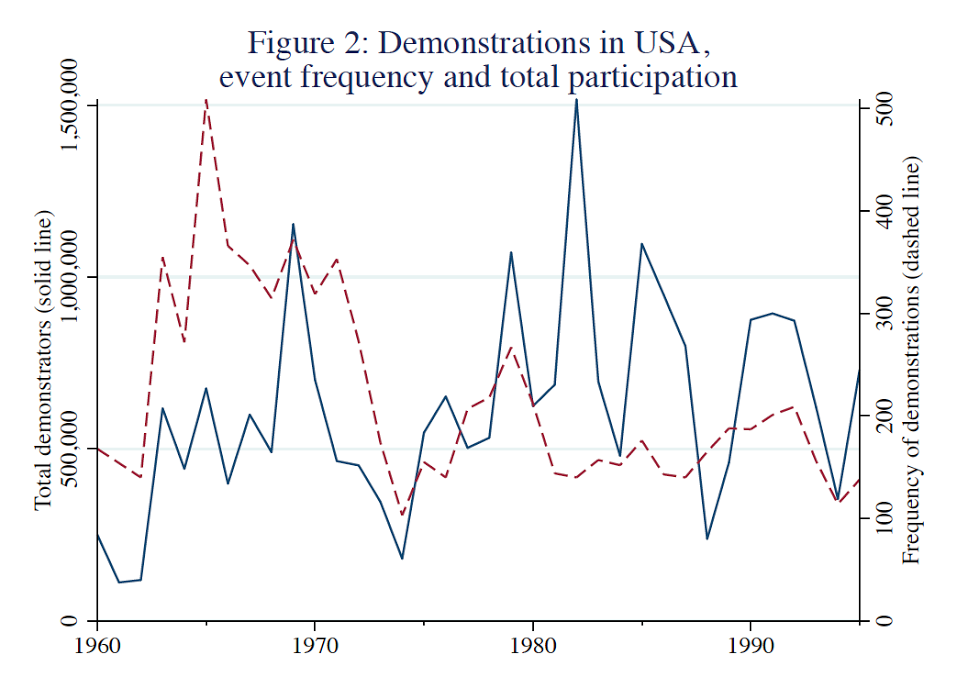
数据库中抗议人数的分布,也呈现出多数抗议规模很小,少数抗议规模极大的特点,即通常所说的长尾分布。不同抗争形式中,骚乱被捕的人数差异是最小的,但其最大值也有中位数的30倍。对于示威游行来说,这一比例更是高达20000倍。1960到1990年代30多年间,几乎每一年的示威参与者,都来自少数几次大型示威。在首都华盛顿,一万人以上的示威只占总数的1%,但是其参加者却占到所有参与人数的69%;一万人以上的罢工只占0.4%,却贡献了56%的总参与者。
如果用我们熟知的基尼系数去描绘抗议人数间的“不平等”,罢工的不平等程度是0.87,而华盛顿示威的“基尼系数”高达0.94!可以想见,如果两位研究者一位采用抗议数量、一位采用抗议规模来揭示社会的走向,其结论会有多大的不同。
变幻的时代与尴尬的数据
学术研究受制于可利用的数据,而数据本身,也深刻影响到了研究的趋势和结论。这种影响不仅仅取决于数据本身真实与否,还在于数据呈现的具体形式。
数据库的组织与利用方式,很多时候是落后于时代变迁的。数据现实与真实现实间的关系是契合还是断裂,当然主要取决于数据构建者,然而研究者至少需要意识到这种契合与断裂的程度。
回到社运的例子。就拿抗议规模的计算来说,即使统计参与人数比统计频次相对靠谱,前者也不能解决所有问题。最近几年在全世界范围内扩散的占领运动,以及数字媒体在此间的介入,就进一步反映出社运研究数据的尴尬之处:不管是人数统计,还是频率计算,似乎都难以真正反映占领的意义。如今的占领一是持续时间长,二是遍地开花,三是更强的线上招募和跨境传播,这就导致研究者有太多不同方法去统计占领的规模。规模可以按照占领天数来计算,可以按照参与人数计算,也可以看占领运动的主场总面积,或者运动呈现的地理分布、运动扩散到的地区总数量,这里的每种计算方式,还存在最高值/平均值,线上/线下参与的选择问题。而当运动扩散到别处,是将其他地区发生的运动看做单独的抗议,还是主抗议的延伸,也是研究者需要做出的选择。不同的计算方式导致的差异,比过去单日爆发的游行和示威更大。
时代在改变,新的抗争模式已经超越了旧的数据系统。没有田野经历的研究者,很容易就可能掉入数字陷阱。
环顾网络,这两年开放数据和基于数据的可视化项目层出不穷,任何一个学过基本统计的人,都可以下载到五花八门的原始数据,通过简单分析而做出自己对社会方方面面的解读。然而我们对于数据的反思,是不是能同步跟上数据增长的速度呢?新的数据不应该仅从量上超越过去,更应该意识到旧数据在组织层面的根本缺陷。同时,谦逊永远应当是社科研究的底色,即使手握大数据,我们对太多的问题也只是隔岸观火。作为信息爆炸时代的读者和研究者,面对一个更高复杂性的世界,我们有责任做出更多的反思。
数据资源
- 《经济学人》整理的近三年街头抗议规模图表:econ.st/1ryl3bI
- 关于抗议的公开数据库资源整理:http://digital-activism.org/resources/open-access-activism-data-sets/
- 《全球整合新闻数据库(GDELT)原始数据:http://gdeltproject.org/data.html#rawdatafiles
参考文献
- Almeida, P. D., & Lichbach, M. I. (2003). To the internet, from the internet: Comparative media coverage of transnational protests. Mobilization: An International Quarterly, 8 (3), 249-272.
- Biggs, M. (2014). Size matters: The perils of counting protest events, under review
- Earl, J., Martin, A., McCarthy, J. D., & Soule, S. A. (2004). The use of newspaper data in the study of collective action. Annual Review of Sociology , 65-80.
- Herkenrath, M., & Knoll, A. (2011). Protest events in international press coverage: An empirical critique of cross-national conflict databases. International Journal of Comparative Sociology, 52 (3), 163-180.

文章版权归原作者所有。
