空气污染数据造假,这些城市嫌疑最大
空气污染数据造假,这些城市嫌疑最大
还记得“我为祖国测空气”运动吗?2011年底,北京雾霾极为严重,但是北京市环保局的官方数据却并很“和谐”,而美国驻华大使馆的监测数据则一度“爆表”。两个来源的数据“打架”,让人们开始怀疑官方数据的可信度。于是,一些民间环保组织和志愿者发起“我为祖国测空气”,期望募捐自购监测设备,以发布独立的空气污染数据,与官方数据“抗衡”。但是,环境监测设备昂贵且专业性强,“小米加步枪”的便携式自测设备的专业性同样备受争议。
那么,问题来了。官方数据是否造假?如果造假的话,如何找到证据?加州大学两位研究者试图通过研究解决这个问题。他们使用2001-2010年的中国113座城市日均空气污染浓度数据,揭示了城市自报数据的造假证据与造假时点。
他们的研究显示:高达一半的城市都存在不同程度的造假嫌疑。有意思但是,城市的官方数据往往倾向于在不易被觉察的时间造假(如能见度高而风速低的时候),以避免被发现。
不过,数据造假并非“天衣无缝”,通过两位作者开发的方法,就可以揭露其篡改行径。两位作者将其形容为“徒劳的修饰”,因为他们认为中国城市篡改空气污染数据是徒劳无益的。
空气污染数据的造假诱因
为了激励城市政府重视空气污染治理,地方官员的政绩考核中往往包括诸如“蓝天数”这样的指标,即全年空气污染指数低于100点的天数。比如环保部开发的“城考”体系,规定环保重点城市全年85%的天数必须达到蓝天标准。
环境保护的重要性越来越强,地方官员的晋升也受其影响,因此他们有动力去达到这些环保考核指标(参见政见介绍的论文 《《怎样让市长关注环境治理?》 )。但治理环境污染的成本高昂,在信息不对称的情况下弄虚作假显得更容易。
由于缺少独立的监督机制,地方官员有强烈的激励去弄虚作假,以低报空气污染数据并获得较佳的考核结果。
数据造假的危害是明显而严重的,因为它减弱了环境监测的预警效应,也剥夺了公民的知情权。如果空气污染非常严重,但官方发布的数据却不予提醒,那么暴露在污染中的市民无异于“躺着中枪”,在毫不知情的情况下承受污染侵害。基于这些被篡改的数据而开展的实证研究,也可能得出错误的结论,而据此提出的政策建议则可能是误导性的,可谓“遗患无穷”。
研究者将数据造假界定为不报告真实污染水平的行为,如篡改数据或隐藏不好的污染数据。值得一提的是,数据造假不包括政府临时关停工厂、单双号限行等策略性行为——无论是2008年的北京奥林匹克运动会还是2010年的上海世博会,以及2014年的北京APEC领导峰会,政府都曾使用类似的手段,以在短期内改善空气质量。这些策略性行为虽然效率不高,但的确在短期内降低了污染程度,因此不能说是数据造假。
揭露数据造假的“福尔摩斯”
揭露数据造假的最佳方式当然是使用独立的数据来源,与官方数据进行比对。但是,这种数据往往很难获取,特别是大样本和跨时期的数据更难找到。
不过,还有别的办法来识破造假的蛛丝马迹。在不存在数据造假的情况下,空气污染浓度的分布应该是连续的或平滑的曲线。当地方官员试图造假时,最有可能在空气污染浓度处于蓝天标准的临界点上(即API为100点)时下手。
这样一来,把略高于临界点的数据稍微拉下来一点,就可以使当天的空气污染数据符合蓝天标准,且不容易被人察觉。如果这种情况三番五次地发生,就可以说明存在数据造假的嫌疑。
研究者的数据来自隶属于环境保护部的中国环境监测总站。它只是汇总各地政府上报的空气污染数据,因此数据如果发生造假,应归因于地方政府。
中国环境监测总站对外披露的数据只有API和主要污染物,而不包括各污染物的具体浓度值。研究者获取了所有详细数据,发现城市的API均值是76.32,蓝天数占84.6%,刚好接近蓝天数的考核标准(85%)。
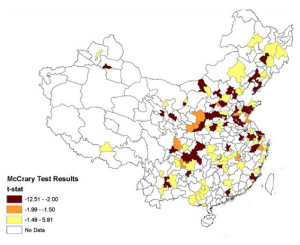
研究者使用一种叫做“断点检验法”的方法,发现数据中的确存在值得关注的造假问题,其表现是:在临界点上出现不连续的断点。
他们发现,大约半数的城市存在捏造PM10污染浓度的嫌疑。但是,二氧化硫和二氧化氮的数据造假并不明显。由于PM10是中国多数城市无法达到蓝天标准的主要诱因(高达73.7%),因此在这个指标上造假就不足为奇了。
找准数据造假的时机
光发现造假只是第一步,下一步是锁定城市造假的时机。这就需要通过适当的匹配方法,将地理位置和省份特征都类似的城市配对。研究者将地理邻近且属于同一个省份的城市配对,获得了13对城市。
在能见度和其他天气情况相同的情况下,配对城市的空气污染程度应该是接近的。如果某个城市出现异常情况,就可以揭示城市在哪些情况下更倾向于造假。
研究者使用的气象和天气数据包括能见度、气温、大气压、降雨量、风速等,其中能见度与空气污染程度的相关程度最高,可以视为空气污染程度的代理指标。气象数据来自美国的国家气候数据中心,天气数据来自中国的国家气象局。由于气象局没有激励去数据造假,因此可以将其报告的数据视为可信的。
借由“面板匹配法”,研究发现:13对城市中有4对没有造假嫌疑,剩下9对都有可能造假。
为了掩人耳目,数据造假最可能发生在异常情况不易被揭发的日子。在能见度高而风速低的时候,数据造假更容易发生。能见度高时,人们会认为空气污染不严重,造假不易被觉察。风速低的时候,空气污染物无法随风而去,需要人为干预以影响空气污染数据。
猫和老鼠的游戏仍将继续下去
这项研究只是说明处于临界点的数据造假更容易发生,但实际上数据造假可以在任何环节出现,因此其严重程度可能被低估了。
该研究列出了数据造假和未造假的城市榜单和地图分布,从中可以发现无论南北、沿海或内地、大城市或小城市,都有造假的嫌疑。
有趣的是,为什么某些城市造假,而另一些城市却没有造假?其背后的原因何在,尚值得未来研究予以揭示。
值得注意的是,2012年新的空气质量标准出台后,特别是国家加强了大气污染防治举措,使各地政府不得不重视空气污染治理。随着各地数据直报系统的逐步建立,以及时均数据的实时发布,都使地方政府干预空气污染数据的可能性大为降低。但是,“道高一尺魔高一丈”,数据造假的新迹象仍有待考察。另外,政见此前曾介绍过两篇有关数据造假的论文,可以作为理解造假行为的参考,它们分别是 《“克强指数”与经济数据造假的政治学》
和 《政绩不够,数字来凑;官出数字,数字出官?》 </br>
参考文献
- Ghanem, D., & Zhang, J. (2014). ‘Effortless perfection:’ Do Chinese cities manipulate air pollution data?. Journal of Environmental Economics and Management, 68 (2), 203-225.

文章版权归原作者所有。
