The European Union Versus the Internet
The European Union Versus the Internet
Earlier this summer the Internet breathed a sigh of relief: the European Parliament voted down a new Copyright Directive that would have required Internet sites to proactively filter uploaded content for copyright violations (the so-called “meme ban”), as well as obtain a license to include any text from linked sites (the “link tax”).
Alas, the victory was short-lived. From EUbusiness :
Internet tech giants including Google and Facebook could be made to monitor, filter and block internet uploads under amendments to the draft Copyright Directive approved by the EU Parliament Wednesday. At their plenary session, MEPs adopted amendments to the Commission’s draft EU Copyright Directive following from their previous rejection, adding safeguards to protect small firms and freedom of expression…
Parliament’s position toughens the Commission’s proposed plans to make online platforms and aggregators liable for copyright infringements. This would also apply to snippets, where only a small part of a news publisher’s text is displayed. In practice, this liability requires these parties to pay right holders for copyrighted material that they make available.
At the same time, in an attempt to encourage start-ups and innovation, the text now exempts small and micro platforms from the directive.
I chose this rather obscure source to quote from for a reason: should Stratechery ever have more than either 50 employees or €10 million in revenue, under this legislation I would likely need to compensate EUbusiness for that excerpt. Fortunately (well, unfortunately!), this won’t be the case anytime soon; I appreciate the European Parliament giving me a chance to start-up and innovate.
This exception, along with the removal of an explicit call for filtering (that will still be necessary in practice), was enough to get the Copyright Directive passed. This doesn’t mean it is law: the final form of the Directive needs to be negotiated by the EU Parliament, European Commission, and the Council of the Europe Union (which represents national governments), and then implemented via national laws in each EU country (that’s why it is a Directive ).
Still, this is hardly the only piece of evidence that EU policy makers have yet to come to grips with the nature of the Internet: there is also the General Data Protection Regulation (GDPR), which came into effect early this year. Much like the Copyright Directive, the GDPR is targeted at Google and Facebook, but as is always the case when you fundamentally misunderstand what you are fighting, the net effect is to in fact strengthen their moats . After all, who is better equipped to navigate complex regulation than the biggest companies of all, and who needs less outside data than those that collect the most?
In fact, examining where it is that the EU’s new Copyright Directive goes wrong — not just in terms of policy, but also for the industries it seeks to protect — hints at a new way to regulate, one that works with the fundamental forces unleashed by the Internet, instead of against them.
Article 13 and Copyright
Forgive the (literal) legalese, but here is the relevant part of the Copyright Directive (the original directive is here and the amendements passed last week are here ) pertaining to copyright liability for Internet platforms:
Online content sharing service providers perform an act of communication to the public and therefore are responsible for their content and should therefore conclude fair and appropriate licensing agreements with rightholders. Where licensing agreements are concluded, they should also cover, to the same extent and scope, the liability of users when they are acting in a non-commercial capacity…
Member States should provide that where right holders do not wish to conclude licensing agreements, online content sharing service providers and right holders should cooperate in good faith in order to ensure that unauthorised protected works or other subject matter, are not available on their services. Cooperation between online content service providers and right holders should not lead to preventing the availability of non-infringing works or other protected subject matter, including those covered by an exception or limitation to copyright…
This is legislative fantasizing at its finest: Internet platforms should get a license from all copyright holders, but if they don’t want to (or, more realistically, are unable to), then they should keep all copyrighted material off of their platforms, even as they allow all non-infringing work and exceptions. This last bit is a direct response to the “meme ban” framing: memes are OK, but the exception “should only be applied in certain special cases which do not conflict with normal exploitation of the work or other subject-matter concerned and do not unreasonably prejudice the legitimate interests of the rightholder.” 1 That’s nearly impossible for a human to parse; expecting a scalable solution — which yes, inevitably means content filtering — is absurd. There simply is no way, especially at scale, to preemptively eliminate copyright violations without a huge number of mistakes.
The question, then, is in what direction those mistakes should run. Through what, in retrospect, are fortunate accidents of history , 2 Internet companies are mostly shielded from liability, and need only respond to takedown notices in a reasonable amount of time. In other words, the system is biased towards false negatives: if mistakes are made, it is that content that should not be uploaded is. The Copyright Directive, though, would shift the bias towards false positive: it mistakes are made, it is that allowable content will be blocked for fear of liability.
This is a mistake. For one, the very concept of copyright is a government-granted monopoly on a particular arrangement of words. I certainly am not opposed to that in principle — I am obviously a benefactor — but in a free society the benefit of the doubt should run in the opposite direction of those with the legal right to deny freedom. The Copyright Directive, on the other hand, requires Internet Platforms to act as de facto enforcement mechanisms of that government monopoly, and the only logical response is to go too far.
Moreover, the cost of copyright infringement to copyright holders has in fact decreased dramatically. Here I am referring to cost in a literal sense: to “steal” a copyrighted work in the analog age required the production of a physical product with its associated marginal costs; anyone that paid that cost was spending real money that was not going to the copyright holder. Digital goods, on the other hand, cost nothing to copy; pirated songs or movies or yes, Stratechery Daily Updates , are very weak indicators at best of foregone revenue for the copyright holder. To put it another way, the harm is real but the extent of the harm is unknowable, somewhere in between the astronomical amounts claimed by copyright holders and the zero marginal cost of the work itself.
The larger challenge is that the entire copyright system was predicated on those physical mediums: physical goods are easier to track, easier to ban, and critically, easier to price. By extension, any regulation — or business model, for that matter — that starts with the same assumptions that guided copyright in the pre-Internet era is simply not going to make sense today. It makes far more sense to build new business models predicated on the Internet.
The music industry is a perfect example: the RIAA is still complaining about billions of dollars in losses due to piracy , but many don’t realize the industry has returned to growth , including a 16.5% revenue jump last year. The driver is streaming, which — just look at the name! — depends on the Internet: subscribers get access to basically all of the songs they could ever want, while the recording industry earns somewhere around $65 per individual subscriber per year with no marginal costs. 3 It’s a fantastic value for customers and an equally fantastic revenue model for recording companies; that alignment stems from swimming with the Internet, not against it.
This, you’ll note, is not a statement that copyright is inherently bad, but rather an argument that copyright regulation and business models predicated on scarcity are unworkable and ultimately unprofitable; what makes far more sense for everyone from customers to creators is an approach that presumes abundance. Regulation should adopt a similar perspective: placing the burden on copyright holders not only to police their works, but also to innovate towards business models that actually align with the world as it is, not as it was.
Article 11 and Aggregators
This shift from scarcity to abundance has also had far-reaching effects on the value chains of publications, something I have described in Aggregation Theory (“ Value has shifted away from companies that control the distribution of scarce resources to those that control demand for abundant ones “). Unfortunately the authors of the Copyright Directive are quite explicit in their lack of understanding of this dynamic; from Article 11 of the Directive:
The increasing imbalance between powerful platforms and press publishers, which can also be news agencies, has already led to a remarkable regression of the media landscape on a regional level. In the transition from print to digital, publishers and news agencies of press publications are facing problems in licensing the online use of their publications and recouping their investments. In the absence of recognition of publishers of press publications as rightholders, licensing and enforcement in the digital environment is often complex and inefficient.
In this reading the problem facing publishers is a bureaucratic one: capturing what is rightfully theirs is “complex and inefficient”, so the Directive provides for “the exclusive right to authorise or prohibit direct or indirect, temporary or permanent reproduction by any means and in any form, in whole or in part” of their publications “so that they may obtain fair and proportionate remuneration for the digital use of their press publications by information society service providers.” 4
The problem, though, is that the issue facing publishers is not a problem of bureaucracy but of their relative position in a world characterized by abundance. I wrote in Economic Power in the Age of Abundance :
For your typical newspaper the competitive environment is diametrically opposed to what they are used to: instead of there being a scarce amount of published material, there is an overwhelming abundance. More importantly, this shift in the competitive environment has fundamentally changed just who has economic power.
In a world defined by scarcity, those who control the scarce resources have the power to set the price for access to those resources. In the case of newspapers, the scarce resource was reader’s attention, and the purchasers were advertisers…The Internet, though, is a world of abundance, and there is a new power that matters: the ability to make sense of that abundance, to index it, to find needles in the proverbial haystack. And that power is held by Google. Thus, while the audiences advertisers crave are now hopelessly fractured amongst an effectively infinite number of publishers, the readers they seek to reach by necessity start at the same place — Google — and thus, that is where the advertising money has gone.
This is the illustration I use to show the shift in publishing specifically (this time using Facebook):
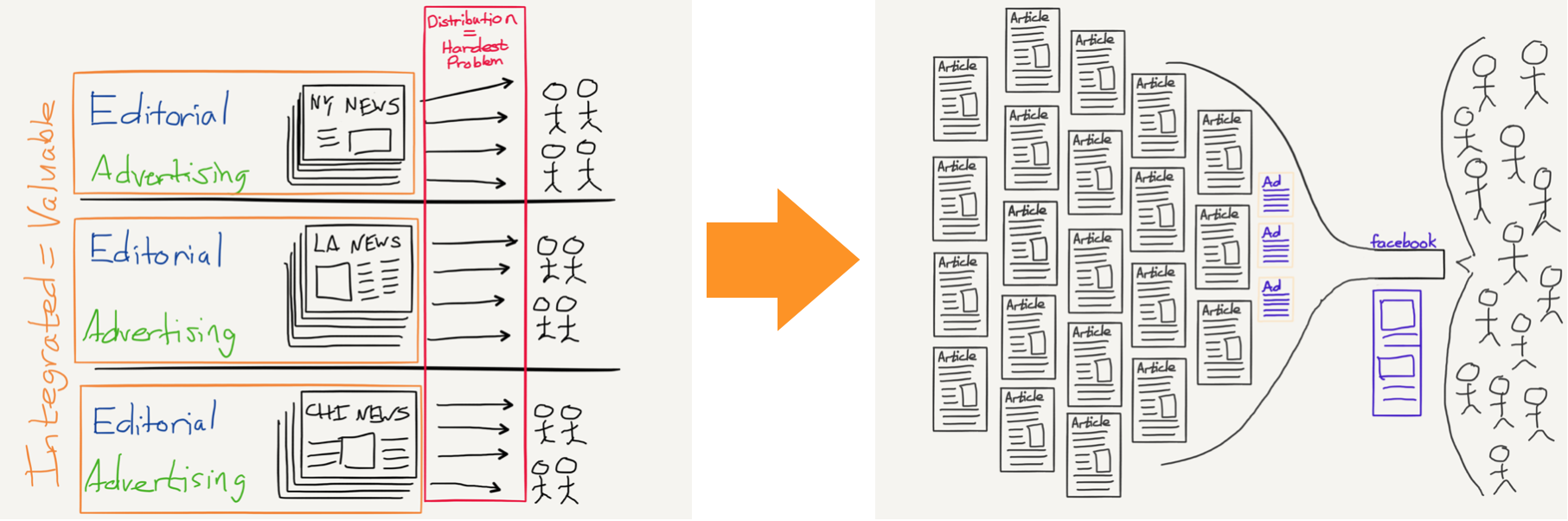
This is why the so-called “link tax” is doomed to failure — indeed, it has already failed every time it has been attempted. Google, which makes no direct revenue from Google News, 5 will simply stop serving Google News to the EU, or dramatically curtail what it displays, and the only entities that will be harmed — other than EU consumers — are the publications that get traffic from Google News. Again, that is exactly what happened previously .
There is another way to understand the extent to which this proposal is a naked attempt to work against natural market forces: Google’s search engine respects a site’s robot.txt file, wherein a publisher can exclude their site from the company’s index. Were it truly the case that Google was profiting unfairly from the hard word of publishers, then publishers have a readily-accessible tool to make them stop. And yet they don’t, because the reality is that while publishers need Google (and Facebook), that need is not reciprocated. To that end, the only way to characterize money that might flow from Google and Facebook (or a €10-million-in-revenue-generating Stratechery) to publishers is as a redistribution tax, enforced by those that hold the guns.
Here again the solution ought to flow in the opposite direction, in a way that leverages the Internet, instead of fighting it. An increasing number of publishers, from large newspapers to sites like Stratechery, are taking advantage of the massive addressable market unlocked by the Internet, leveraging the marketing possibilities of free social media and search engine results, and connecting directly with readers that care — and charging them for it.
I do recognize this is a process that takes time: it is particularly difficult for publishers built with monopoly-assumptions to change not just their business model but their entire editorial strategy for a world where quality matters more than quantity. To that end, if the EU wants to, as they say in the Copyright Directive, “guarantee the availability of reliable information”, then make the tax and subsidy plan they effectively propose explicit. At least then it would be clear to everyone what is going on.
The GDPR and the Regulatory Corollary of Aggregation
This brings me to a piece of legislation I have been very critical of for quite some time: GDPR. The intent of the legislation is certainly admirable — protect consumer privacy —although (and this may be the American in me speaking) I am perhaps a bit skeptical about just how much most consumers care relative to elites in the media. Regardless, the intent matters less than the effect, the latter of which is to entrench Google and Facebook. I wrote in Open, Closed, and Privacy :
While GDPR advocates have pointed to the lobbying Google and Facebook have done against the law as evidence that it will be effective, that is to completely miss the point: of course neither company wants to incur the costs entailed in such significant regulation, which will absolutely restrict the amount of information they can collect. What is missed is that the increase in digital advertising is a secular trend driven first-and-foremost by eyeballs: more-and-more time is spent on phones, and the ad dollars will inevitably follow. The calculation that matters, then, is not how much Google or Facebook are hurt in isolation, but how much they are hurt relatively to their competitors, and the obvious answer is “a lot less”, which, in the context of that secular increase, means growth.
This is the conundrum that faces all major Internet regulation, including the Copyright Directive; after all, Google and Facebook can afford — or have already built — content filtering systems, and they already have users’ attention such that they can afford to cut off content suppliers. To that end, the question is less about what regulation is necessary and more about what regulation is even possible (presuming, of course, that entrenching Google and Facebook is not the goal).
This is where thinking about the problems with the Copyright Directive is useful:
- First, just as business models ought to be constructed that leverage the Internet instead of fight it, so should regulation.
- Second, regulation should start with the understanding that power on the Internet flows from controlling demand, not supply.
To understand what this sort of regulation might look like, it may be helpful to work backwards. Specifically, over the last six months Facebook has made massive strides when it comes to protecting user privacy. The company has shut down third-party access to sensitive data, conducted multiple audits of app developers that accessed that data, added new privacy controls, and more. Moreover, the company has done this for all of its users, not just those in the EU, suggesting its actions were not driven by GDPR.
Indeed, the cause is obvious: the Cambridge Analytica scandal, and all of the negative attention associated with it. To put it another way, bad PR drove more Facebook action in terms of user privacy than GDPR or a FTC consent decree . This shouldn’t be a surprise; I wrote in Facebook’s Motivations :
Perhaps there is a third motivation though: call it “enlightened self-interest.” Keep in mind from whence Facebook’s power flows: controlling demand. Facebook is a super-aggregator , which means it leverages its direct relationship with users, zero marginal costs to serve those users, and network effects, to steadily decrease acquisition costs and scale infinitely in a virtuous cycle that gives the company power over both supply (publishers) and advertisers.
It follows that Facebook’s ultimate threat can never come from publishers or advertisers, but rather demand — that is, users. The real danger, though, is not from users also using competing social networks (although Facebook has always been paranoid about exactly that); that is not enough to break the virtuous cycle. Rather, the only thing that could undo Facebook’s power is users actively rejecting the app. And, I suspect, the only way users would do that en masse would be if it became accepted fact that Facebook is actively bad for you — the online equivalent of smoking.
For Facebook, the Cambridge Analytica scandal was akin to the Surgeon General’s report on smoking : the threat was not that regulators would act, but that users would, and nothing could be more fatal. That is because:
The regulatory corollary of Aggregation Theory is that the ultimate form of regulation is user generated .
If regulators, EU or otherwise, truly want to constrain Facebook and Google — or, for that matter, all of the other ad networks and companies that in reality are far more of a threat to user privacy — then the ultimate force is user demand, and the lever is demanding transparency on exactly what these companies are doing.
To that end, were I a regulator concerned about user privacy, my starting point would not be an enforcement mechanism but a transparency mechanism. I would establish clear metrics to measure user privacy — types of data retained, types of data inferred, mechanisms to delete user-generated data, mechanisms to delete inferred data, what data is shared, and with whom — and then measure the companies under my purview — with subpoena power if necessary — and publish the results for the users to see.
This is the way to truly bring the market to bear on these giants: not regulatory fiat, but user sentiment. That is because it is an approach that understands the world as it is, not as it was, and which appreciates that bad PR — because it affects demand — is a far more effective instigator of change than a fine paid from monopoly profits.
I wrote a follow-up to this article in this Daily Update .
- Full text of the “meme exception”:
文章版权归原作者所有。
