In 1990, Congress passed the Nutrition Labeling and Education Act, which required nutrition labels for nearly all packaged food products; the label includes a standard serving measurement, calories per serving, and the “% Daily Value” for nutrients like fat, cholesterol, sodium, carbohydrates, protein, and a number of vitamins and minerals. For many consumers, though, labels were like road signs: they provided tactical assistance while grocery shopping, but you still needed a map for how to eat.
Enter the food pyramid, which was introduced by the U.S. Department of Agriculture in 1992:
The concept is a simple one: according to the USDA, consumers should eat a lot of carbohydrates, some vegetables and fruit, a small amount of dairy and proteins, and as little fat as possible. It was also completely wrong. Scientific American noted in 2006:
Even when the pyramid was being developed, though, nutritionists had long known that some types of fat are essential to health and can reduce the risk of cardiovascular disease. Furthermore, scientists had found little evidence that a high intake of carbohydrates is beneficial. After 1992 more and more research showed that the USDA pyramid was grossly flawed. By promoting the consumption of all complex carbohydrates and eschewing all fats and oils, the pyramid provided misleading guidance. In short, not all fats are bad for you, and by no means are all complex carbohydrates good for you.
Road signs are well and good, but if they get you to a place you may not want to be going, they may not be as valuable as they seem. To that end, let me be clear about my goals for this Article, which is going to be both more critical of Apple and more gracious to Facebook than the conventional wisdom about privacy on the Internet: you don’t have to agree with my conclusions, but I will feel I have accomplished my job if you can at least see that everything in this space comes with tradeoffs.
Privacy Nutrition Labels
Starting today Apple will require all new apps and app updates submitted to the App Store to include detailed information about their data collection practices; these submissions will manifest to customers in the form of “Privacy Nutrition Labels”, which Apple introduced at WWDC in June:
There is, as you might expect from an Apple marketing presentation, nothing that seems objectionable, and a whole lot that is worth celebrating: of course consumers should want information that…well, what is this information used for? Apple, in a recent advertisement, provided the food pyramid to their nutrition labels:
This is truly scandalous, but not for the reason Apple wants you to think it is: the way in which this ad depicts how your information is used — literally broadcasting your web browsing and searches and private conversations to those around you — is so misleading that it is hard to call it anything but misinformation.
And yet, I can understand why some celebrated the ad, because the fact of the matter is that all of the information depicted in the commercial (except, in more and more cases, private chats, which are increasingly encrypted), are collected, particularly by Facebook.
Lookalike Audiences
Let’s grant, for the sake of this article, that Facebook is collecting vast quantities of information about you, whether that be through activity on Facebook properties, activity in apps that have embedded Facebook’s SDK, or activity on websites with Facebook pixels embedded. Let’s further assume that Facebook has taken that data and combined it with information from Facebook advertisers and other publicly available data sources in what I have previously called a Data Factory:
Facebook quite clearly isn’t an industrial site (although it operates multiple data centers with lots of buildings and machinery), but it most certainly processes data from its raw form to something uniquely valuable both to Facebook’s products (and by extension its users and content suppliers) and also advertisers (and again, all of this analysis applies to Google as well).
I prefer the term “Data Factory” to “Data Refinery”, because processed data isn’t really a fungible good: while oil from one refinery is no different than oil from another, and priced identically, Facebook data is valuable only to the extent that it is usable on Facebook, which primarily means an advertising approach called “lookalike audiences.” From the Facebook Business Help Center:
When you create a Lookalike Audience, you choose a source audience (a Custom Audience created with information pulled from your pixel, mobile app, or fans of your Page). We identify the common qualities of the people in it (for example, demographic information or interests). Then, we deliver your ad to an audience of people who are similar to (or “look like”) them.
You can choose the size of a Lookalike Audience during the creation process. Smaller audiences more closely match your source audience. Creating a larger audience increases your potential reach, but reduces the level of similarity between the Lookalike Audience and source audience. We generally recommend a source audience with between 1,000 to 50,000 people. Source quality matters too. For example, if a source audience is made up of your best customers rather than all your customers, that could lead to better results.
This is actually a rather fair representation of how lookalike audiences work, but of course the scary details are hidden between the lines; let me try and make them explicit:
As noted above, Facebook really is tracking you everywhere, both on Facebook and off, with the eager cooperation of both publishers and app developers (you will understand why shortly).1 All of this data builds a far more in-depth behavior profile than Facebook’s anodyne “demographic information or interests” language suggests.
A third-party, meanwhile, has a list of profitable customers. For a game maker, this might be a list of Identifier for Advertisers (IDFAs) of users that made a considerable number of in-app purchases; for an e-commerce site, this might be a list of email addresses. Naturally, said third-party would like to find more gamers who will make in-app purchases, or customers who will buy products.
Lookalike audiences accomplish exactly that: the third-party can upload their list of profitable customers2 and set the maximum price they are willing to pay to acquire those customers. Facebook will then find other Facebook users that “look like” them, using its data factory, and show ads to those users, with the price based on an instantaneous auction between all of the different advertisers seeking to reach those particular customers.
I get why this sounds creepy; it would be pretty disturbing if a salesperson showed up at my door to inform me that someone who visits the same websites I do just bought this really neat grilling implement, which means I might be interested in said grilling implement as well. The fact that said salesperson is probably right — I do love my grilling implements! — makes it even creepier. This, though, is by-and-large what is happening when you see that scarily accurate Instagram advertisement.
Except that this isn’t what is happening at all.
Tradeoffs and Computer Scale
What makes that Apple advertisement so misleading is the level of individuality it implies in terms of data collection and application. Individuality is a real problem when it comes to data collection; in 2019’s Privacy Fundamentalism I included a photo of the East German Stasi Archives from Wired and noted:
That the files are paper makes them terrifying, because anyone can read them individually; that they are paper, though, also limits their reach. Contrast this to Google or Facebook: that they are digital means they reach everywhere; that, though, means they are read in aggregate, and stored in a way that is only decipherable by machines.
To be sure, a Stasi compare and contrast is hardly doing Google or Facebook any favors in this debate: the popular imagination about the danger this data collection poses, though, too often seems derived from the former, instead of the fundamentally different assumptions of the latter. This, by extension, leads to privacy demands that exacerbate some of the Internet’s worst problems.
Facebook’s crackdown on API access after Cambridge Analytica has severely hampered research into the effects of social media, the spread of disinformation, etc.
Privacy legislation like GDPR has strengthened incumbents like Facebook and Google, and made it more difficult for challengers to succeed.
Criminal networks from terrorism to child abuse can flourish on social networks, but while content can be stamped out, private companies — particularly domestically — are often limited as to how proactively they can go to law enforcement; this is exacerbated once encryption enters the picture.
That last point provides the most trenchant example of how privacy rules that don’t consider trade-offs can go wrong; from the New York Times late last week:
Privacy concerns in Europe have led to some of the world’s toughest restrictions on companies like Facebook and Google and the ways they monitor people online. The crackdown has been widely popular, but the regulatory push is now entangled in the global fight against child exploitation, setting off a fierce debate about how far internet companies should be allowed to go when collecting evidence on their platforms of possible crimes against minors.
A rule scheduled to take effect on Dec. 20 would inhibit the monitoring of email, messaging apps and other digital services in the European Union. It would also restrict the use of software that scans for child sexual abuse imagery and so-called grooming by online predators. The practice would be banned without a court order.
Those European rules comes from a perception of online privacy that looks a lot like that Apple advertisement: companies clicking through your email and social network accounts, carefully charting everything you do, just so they can show an ad. Why would you not want to stop such creepy behavior?
The reality, though, is that nearly all of the child pornography reported to authorities is found by automatically scanning images and comparing them to a repository of known illegal images housed by the National Center for Missing and Exploited Children; there are no humans involved, and not only because it is a crime to even view these horrific images: it is completely impossible to do this work at human scale, but automated scanning, computation, and comparisons, are precisely the sort of work that computers are good at.
The Analog Advertising Era
The stakes for online advertising are, of course, massively lower; the reason for the previous section — beyond raising awareness about the massive downside of this new E.U. rule — is not to infer any sort of comparison in either importance or trade-offs. The relevant point, rather, is the last one: computer scale is so different from human scale that analogizing from one to the other is like using a map of Australia to navigate America.
Consider, for example, this letter from Apple’s Senior Director of Global Privacy Jane Horvath assuaging concerns that Apple had lost its nerve in terms of implementing its App Tracking Transparency (ATT) feature, which disables the aforementioned IDFA unless customers opt-in (Apple delayed the implementation to next year):
Advertising that respects privacy is not only possible, it was the standard until the growth of the Internet. Some companies that would prefer ATT is never implemented have said that this policy uniquely burdens small businesses by restricting advertising options, but in fact, the current data arms race primarily benefits big businesses with big data sets. Privacy-focused ad networks were the universal standard in advertising before the practice of unfettered data collection began over the last decade or so. Our hope is that increasing user demands for privacy and security, as well as changes like ATT, will make these privacy-forward advertising standards robust once more.
The fact that pre-Internet advertisers were limited to mediums like TV had profound implications that went far beyond privacy; as I explained in 2016’s TV Advertising’s Surprising Strength — And Inevitable Fall, the entire post-World War II economic order was built around the opportunities and limitations offered by analog advertising.
Content companies, from TV stations to radio stations to newspapers, were incentivized to produce broadly appealing content that applied to the maximum number of people, in order to both maximize the number of consumers for advertisers and also to avoid any uncomfortable antitrust questions about their control of scarce mediums.
Consumer packaged goods companies of all types, from household products to food companies to clothing brands, were similarly incentivized to produce lowest-common-denominator products that would appeal to the most people possible, and advertise them on those mass market media channels.
Retailers increasingly consolidated and increased in size, culminating in massive outlets with even larger parking lots, the better to both house all of those CPG products — who bid against each other for scarce shelf space — and also to capture an increasingly suburban clientele that preferred a big house with a TV room over a smaller residence in big cities.
There were certainly advantages to this state of affairs, particularly when viewed through the rose-tinted glasses of nostalgia: a limited number of ways to get middle-of-the-road content, for example, offered a shared source of truth that made it easier to find common political ground;3 large and predictable markets worked to the benefit of large and profitable conglomerates that provided millions of middle class jobs; and, of course, the fundamental limitations of the analog world — which operates at human scale — meant that “advertising that respects privacy…was the standard.”
All of these changes, in fact, are about exceeding human scale via technology and the Internet, and is it any surprise that advertising has gone through the exact same transformation? When I write a post on Stratechery, I am not driving to your door and reading these words aloud to you; in fact, I don’t have any idea who you are. Computers take care of moving these bits from my computer to yours. It’s the same thing with an app developer creating in-app purchases, or an e-commerce site selling grilling implements: the entire reason their businesses are possible is precisely because they don’t know who I am, and have no reason to. And yet they can sell me exactly what I want just the same.
Growing Internet GDP
I am, by virtue of temperament, experience, and self-interest, an Internet optimist. The fact that you can access information anywhere meant I could learn anywhere, whether that be small-town Wisconsin or big-city Asia. And, once I had leavened that learning with enough education and work experience to be dangerous, I could create a business that has the entire globe as its addressable market. Of course I didn’t do this alone: the Stratechery stack is dependent on a host of services like Stripe, which I wrote about last week: thanks to the ability to collect credit card payments from anyone I have helped “increase the GDP of the Internet”, to quote the platform company’s mission statement.
Increasing the GDP of the Internet is important precisely because of all of the upheaval I just described: just because the way in which our economy was organized in an analog world is being upset by the Internet, it does not necessarily follow that what comes next will be better. It is possible to imagine, though, what “better” looks like: individuals and small companies leveraging the Internet to deliver individuals and small groups exactly what they want.
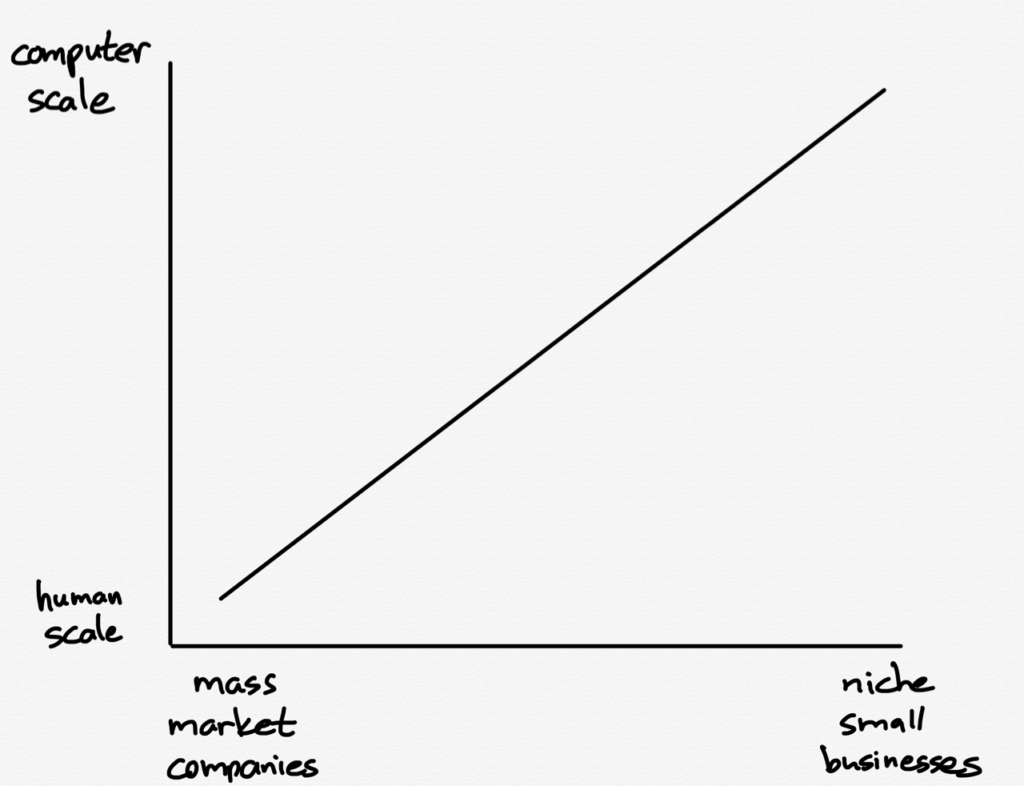
This is the paradox of the Internet: computer scale unlocks human level opportunities, in contrast to the analog world where human scale gave the edge to large companies. You might imagine a graph that looks something like this:
This is not to scale (pun very much intended): the biggest platforms, from Shopify to Stripe, are off the chart, given the fact they connect everyone on the planet, whereas even the biggest multinationals are limited by geography, shelf space, and distribution costs. That’s ok, though: they are also limited in where they can advertise, as well.
Niche products and publications, on the other hand, can build sustainable businesses with customers across the entire world who have nothing in common except a shared interest in the product or publication in question; or, to put it another way, customers who “lookalike”. That’s the thing about Facebook and other digital advertising companies: they are just as essential a part of growing the GDP of the Internet as are Stripe and Shopify and other companies with universal approval ratings. It is no good to be capable of serving anyone anywhere if they can’t find you.
The Internet’s Choice
This is the beginning of the defense of Facebook’s approach to advertising, but not the end; after all, no matter what Apple’s Senior Director of Global Privacy may argue, we are not returning to a world defined by TV advertising from large CPG companies that gave middle class employees jobs for life. The Internet offers two clear alternatives: either a million blooming flowers, or all-encompassing behemoths that succeed by controlling access to customers. In the case of information, that alternative is Google, and in the case of products, it is Amazon.
What is notable about both is how relatively untouched they are by Apple’s privacy campaign. Yes, Google has app SDKs, but they also have an even larger presence on the web than Facebook, have somewhat less need for data given the directed nature of search advertising, and oh yeah, are the default search engine on Apple devices, which makes it that much easier to ensure that information flows via Google’s channels (like AMP pages, which get around Apple’s recent cookie-crackdowns by being served from Google’s own URL). And, of course, there is Android and Chrome, which gives Google far deeper access to all of the information it could ever want than Facebook could even dream of.
Amazon, meanwhile, is increasingly where shopping searches start, particularly for Prime customers, and the company’s ad business is exploding. Needless to say, Amazon doesn’t need to request special permission for IDFAs or to share emails with 3rd parties to finely target its ads: everything is self-contained, and to the extent the company advertises on platforms like Google, it can still keep information about customer interests and conversions to itself. That means that in the long run, independent merchants who wish to actually find their customers will have no choice but to be an Amazon third-party merchant instead of setting up an independent shop on a platform like Shopify.
This decision, to be clear, will not be because Amazon was acting anticompetitively; the biggest driver — which, by the way, will also benefit Facebook’s on-platform commerce efforts — will be Apple, which, in the pursuit of privacy, is systematically destroying the ability of platform-driven small businesses to compete with the Internet giants.
Facebook Fats
Apple’s means are, I should note, anticompetitive in spirit, if not in law; the company’s policies are predicated on control of the App Store, and a demonstrated willingness to use its power to get its way. That is how the company can not only disable access to the IDFA programmatically, but also demand that apps disclose what information they send to their own servers using open Internet protocols.
Leaving aside legality, though, it is notable that Apple is quite obviously swimming against the prevailing current. That current, I would argue, is not greedy companies pushing the limits just because they can, but rather the fundamental nature of computers and the Internet. Computers emit data as a matter of course, and the Internet makes the transfer of that data free. To strive for a world without the generation or capture of data is to fight against the very nature of technology.
This is not, to be very clear, to excuse the worst abuses of this capability (which, notably, are third-party advertising networks that, unlike social media companies, actually do sell your data), but simply to acknowledge its reality; this acceptance is crucial, because it shows why Apple’s map is wrong: the company is less protecting customers from Facebook than it is protecting Google and Amazon and other centralized consumer services from independent competition. Just think about it: small companies can only compete against the big guys if they can work together, whether that means collectively using services like Stripe and Shopify, or advertising — with their shared data, via lookalike audiences — on platforms like Facebook.
I get that this is not a particularly popular position, and Facebook sure doesn’t make it easy to hold to. I remain very concerned about the company’s power and impact on everything from information dissemination to radicalization to yes, privacy. At the same time, the USDA was not necessarily wrong to say that some fats could be dangerous; rather, the mistake was in operating in broad generalizations, leading normal folks simply doing their best to adopt carbohydrate-heavy diets that were even worse. Apple’s appeals to analog analogies and simplistic presentation of privacy trade-offs risks a similar path when it comes to the GDP of the Internet and to what extent power is disbursed versus centralized.
Everything in moderation.
For the record, Stratechery does not have the Facebook pixel — the share button below is pure HTML — and does not use lookalike audiences; in fact, as noted in Stratechery’s Privacy Policy, I do not share any user data with any third parties.
A source audience has to have at least 100 people from a single country, both for effectiveness and to prevent privacy violations