挖掘AI:机器学习训练集中的图像政治 - iYouPort
挖掘AI:机器学习训练集中的图像政治
- 这个问题很重要 — — 尤其是对于那些有资源和能力在机器学习上大举投入的国家的公民来说,是的,中国和美国;这两个国家的技术人员应该明白,关于您的工作正在造成什么。这并不是一个关于 “我们如何能令技术更加完善” 的问题,而是,这种技术是否应该存在。这事关反抗、人权、自由和自决,它们是否还能具备原本的意义。

你打开了一个用于训练人工智能系统的图片数据库。
起初,事情似乎很简单。你遇到了数千张图片:苹果和橘子、鸟、狗、马、山、云、房子和路标。但当你进一步探究数据集时,人开始出现:啦啦队员、潜水员、电焊工、童子军、消防员、花童 ……
事情开始变得奇怪了。
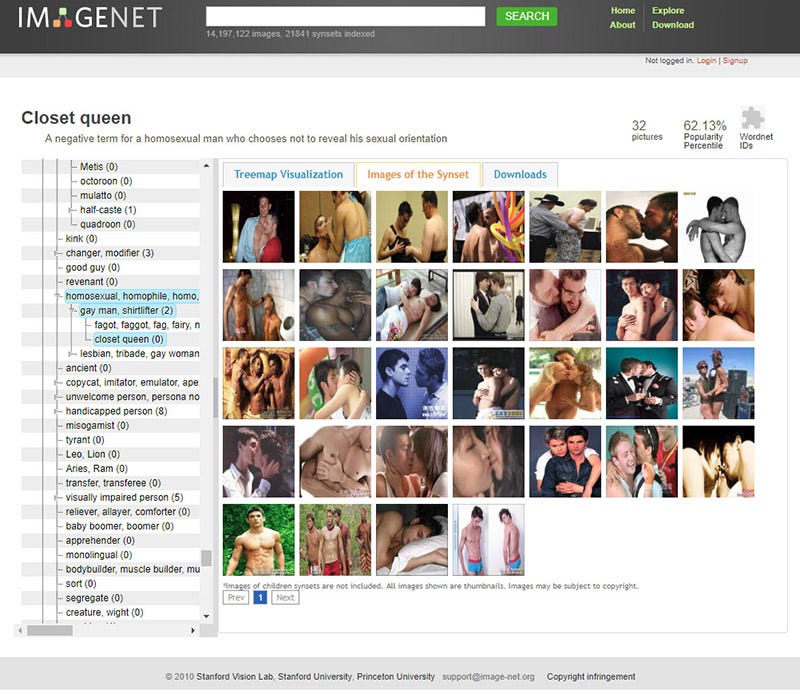
一张穿着比基尼微笑的女人的照片被贴上了 “淫荡,放荡,邋遢的女人,荡妇” 的标签;一个喝啤酒的年轻人被归类为 “酗酒者、酒鬼、饮酒狂、海量、烈酒癖”;一个戴着墨镜的孩子被归类为 “失败者、不务正业的人、不成功人士” ……
你正在查看的是一个名为 ImageNet 的数据集中的 “人” 这一类别,ImageNet 是机器学习中被使用最广泛的训练数据集之一。
这些图片好像哪里有问题。
这些图片是从哪来的?为什么要给照片中的人贴上这样的标签? 当图片与标签配对时,是什么样的政治在起作用?当它们被用来训练技术系统时,又会产生什么样的影响?
简而言之,我们是如何走到这一步的?

关于机器视觉的早期阶段有一个都市传说,机器视觉是人工智能(AI)中关注教会机器检测和解释图像的子领域。1966年,Marvin Minsky 是麻省理工学院的一位年轻教授,在人工智能这个新兴的领域闯出了名堂,Minsky 认为解读图像的能力是智能的核心特征,于是他求助于一位本科生 Gerald Sussman,让他 “花一个夏天的时间,把一台摄像机和一台计算机连接起来,让计算机描述它所看到的东西。
这就成了那个著名的 “夏日远景” 计划(Summer Vision Project),不用说,让计算机 “看” 的项目比任何人预想的都要难得多,所需要的时间也要比一个夏天的时间长得多。
我们 被告知的故事 是这样的:杰出的人们在计算机视觉问题上钻研了几十年,在合适的情况下开始进行,直到20世纪90年代转向概率建模和机器学习技术,加速了进展。这导致了当前的时刻,在这个时刻,诸如物体检测和面部识别等挑战已经基本解决了。 这种 叙事 在许多人工智能的叙述中反复出现,它们在假定持续的技术改进将解决所有问题和打破限制。
但是,如果情况正好相反呢?如果让计算机 “描述他们所看到的” 的挑战将永远是一个问题呢?
在这篇文章中,我们将探讨为什么 图像的自动解释是一个内在的社会和政治项目,而不是一个纯粹的技术项目 。 理解人工智能系统内部的政治性比以往任何时候都重要,因为它们正在迅速进入社会机构的架构中:决定哪个面试者能获得工作、哪些学生在课堂上可以专心听讲、哪些嫌疑人应该被抓捕,以及其他很多事。
- 关于这点,详见分析《 说谎的眼睛:根植于维多利亚时代面部识别 》
- 以及《 来自中国和美国的政府监视:7个危险的用例 》
- 还有《 “帮派数据库”是什么?为什么据此就可以直接给无辜的市民定下重罪? 》
在过去的两年里,人们一直在研究如何利用图像来训练人工智能系统 “看” 世界的基本逻辑。研究了人工智能中使用的数百个图像集合,从20世纪60年代初的面部识别的首次实验到包含数百万张图像的当代训练集。
从方法论上讲,可以把这个项目称为数据集的考古学:我们一直在挖掘材料层,编目一些东西被构建的原则和价值,并分析哪些规范的生活模式被假设、支持和复制。
通过挖掘这些训练集的构造及其底层结构,许多毋庸置疑的假设被揭示出来。 这些假设的揭示为帮助人们了解人工智能系统的工作方式和失败方式提供了重要信息,直到今天。
这篇文章从一个看似简单的问题开始。图像在人工智能系统中做什么工作?计算机要在图像中识别什么,什么是被误认甚至完全看不见的?
接下来,我们看看将图像引入计算机系统的方法,看看分类法如何对基础概念进行排序,这些概念将成为计算机系统可以理解的概念。
然后,我们转向标记的问题:人类如何告诉计算机哪些词将与给定的图像有关?而人工智能系统使用这些标签对人类进行分类的方式,包括按种族、性别、情感、能力、性别和个性进行分类,这其中又有什么利害关系?
最后,我们转而讨论计算机视觉在我们的社会中要达到的目的 —— 为计算机提供这些能力的判断、选择和后果。

训练AI
构建AI系统需要数据。为识别物体或识别人脸而设计的监督式机器学习系统是在由许多离散图像组成的数据集中包含的大量数据上进行训练的。
例如,为了构建一个能够识别苹果和橙子的图片之间的差异的计算机视觉系统,开发人员必须收集、标记、并在数千张标记了苹果和橙子的图像上训练一个神经网络。在软件方面,算法对这些图片进行统计调查,并开发出一个模型来识别两个 “类” 之间的差异。
如果一切按计划进行,训练好的模型将能够区分出以前从未遇到过的苹果和橙子的图像之间的差异。

因此, 训练数据集是当代机器学习系统构建的基础,它们是AI系统如何认识和解释世界的核心 。这些数据集塑造了支配人工智能系统如何运作的认识论边界,因此是理解有关人工智能的社会意义问题的一个重要部分。
但是, 当您审视计算机视觉系统中广泛使用的训练图像时,就会发现一个由不稳定的和歪曲的假设构成的基础。
由于计算机视觉领域很少讨论的原因,尽管麻省理工学院这样的机构以及谷歌和 Facebook 这样的公司已经做了很多工作, 但解释图像的项目是一项深层次的复杂和关系性的工作。图像是非常狡猾的东西,充满了多种潜在的意义、无法解决的问题和矛盾。哲学、艺术史和媒体理论的整个子领域都致力于探索图像和意义之间不稳定关系的所有微妙差别。

图像并不能描述自己。这是几个世纪以来艺术家们一直在探索的一个特点。Agnes Martin 创作了一幅网格状的画,并将其命名为 “白花”,就是上面这样;Magritte 画了一幅苹果的图,并写上 “这不是苹果”。
当人们看到这些图像的标签时,就会有不同的看法。这就是图像的政治。
图像、标签和参照物之间的回路是灵活的,可以用任何方式重构,做不同的工作。更重要的是,这些回路可以随着时间的推移而改变,因为图像的文化背景发生了变化,并且可以根据谁在看、他们在哪看,而意味着完全不同的东西。图像是可以被解释和重新解释的。
这也是为什么物体识别和分类的任务比 Minksy —— 以及后来的许多人 —— 最初所想象的要复杂得多的部分原因。
尽管人们普遍认为人工智能和它所借鉴的数据是在客观、科学地对世界进行分类,但是, 到处都是政治、意识形态、偏见、以及历史上所有主观的东西。当您调查最广泛使用的训练数据集时就会发现,这是规则而不是例外。

对训练集的剖析
虽然不同的训练集的目的和架构可能有很大的差异,但它们有一些共同的属性。从核心上来说,成像系统的训练集由一组以各种方式标记并分类的图像组成。
因此,我们可以将它们的整体架构描述为一般由三层组成:整体分类学(类的集合和它们的层次嵌套,如果适用的话)、单个类(图像被组织成的单一类别,例如 “苹果”)、以及每个单独标记的图像(即 被标记为苹果的单个图片)。我们的论点是: 给定训练集架构的每一层都注入了政治。
以 “日本女性面部表情( JAFFE )数据库” 这样的数据集为例,它是由 Michael Lyons、Miyuki Kamachi 和 Jiro Gyoba 在1998年开发的,并广泛用于情感计算研究和开发。
该数据集包含了10位日本女模特的照片,她们做出了7种面部表情,这些表情旨在与7种基本的情感状态相关(该数据集的预期目的是帮助机器学习系统识别和标记这些情感,用于新捕获的、未标记的图像)。
这里隐含的顶层分类法是类似于 “描绘日本女性情绪的面部表情”。
如果我们从分类学上往下走,就会得出类的层次。在JAFFE的情况下,这些类别是快乐、悲伤、惊讶、厌恶、恐惧、愤怒和中性。这些类别成为了收纳箱,所有的单个图像都被存储到其中。
在一个用于面部识别的数据库中,作为另一个例子, 这些类可能对应于数据集中面孔的个人名字 。就如在一个用于对象识别的数据集中,这些类对应的是苹果和橘子这样的东西。 它们 —— 就是你的名字 —— 在此处是用来对底层图像进行排序的不同概念。
在训练集架构的最细层次上,你会找到个体被标记的图像:无论是被标记为表示情绪状态的人脸、还是特定的人、或者是特定的物体,以及其他很多例子。对于 JAFFE 来说,你可以在这里找到一个女人在龇牙咧嘴、微笑、或者看起来很惊讶的样子的图像。
JAFFE 集有几个隐含的论断。首先是分类法本身:“情感” 被视为一组有效的视觉概念。然后是一连串的附加假设:“情绪” 中的概念被认为可应用于人们的面部照片(特别是日本女性);有六种情绪加上一种中性状态;一个人的面部表情和此人的真实情绪状态之间被认为有一种 “固定的关系”;面部和情绪之间的这种关系在这些照片中的女性身上是一致的、可测量的、统一的。
在类的层面上,你会发现诸如这样的东西: “有这样一种 ‘中性’ 的面部表情” 和 “重要的六种情绪状态是快乐、悲伤、愤怒、厌恶、害怕、惊讶。”
在标记图像的层面上,还有其他隐含的假设,如 “这张特殊的照片 描绘的是 一个女人的 ‘愤怒’ 的面部表情”, 而不是 例如,这是一个女人在 **模仿** 愤怒表情的图像。
当然, 这些都是 “表演” 出来的表情 —— 与任何内在状态无关,而是在实验室的环境中表演出来的。每一个层面上的隐含定义充其量都是有待商榷的,而有些定义更是饱受争议。
- 关于这种贴标签的做法为什么是荒唐的和比如错误的 ,详细解释见 《 说谎的眼睛:根植于维多利亚时代面部识别 》
就当代的一大堆训练集而言,JAFFE 训练集还算是相对温和的呢。它是在社交媒体出现之前创建的 —— 在开发者能够大规模从互联网上搜刮图片之前、在亚马逊的 Mechanical Turk 等零散的在线劳动平台允许研究人员和企业随意标注大量照片的艰巨任务之前。
随着训练集的规模和范围越来越大,由其构成的复杂性、意识形态、符号学和政治也越来越多。为了看到这一点,接下来我们将看看最具代表性的训练集,ImageNet。
- 不要错过一些很棒的符号学反抗故事《 政治涂鸦和隐藏的信息:标志、符号和其他视觉线索协助追踪调查的入门指南 》
样板培训集:ImageNet
迄今为止,人工智能历史上最重要的训练集之一就是 ImageNet。ImageNet 在2009年首次以研究海报的形式呈现,是一个范围和雄心都非同一般的数据集。用它的创造者斯坦福大学计算机科学教授李飞飞的话说,ImageNet 背后的想法是 “绘制出整个物体世界的地图。”
在几年的开发过程中,ImageNet 发展得非常巨大: 其开发团队从互联网上搜罗了几百万张图片的集合,并短暂地成为了亚马逊 Mechanical Turk 的全球最大学术用户,使用一支零散的工人队伍,平均每分钟将50张图片分拣成数千个类别。
完成后,ImageNet 由1400多万张标签图片组成,整理成2万多个类别。十年来,它一直是机器学习物体识别的巨无霸,也是该领域强大的重要标杆。
【注:Amazon Mechanical Turk 是一个众包网站,供企业雇用远程工作的 “众包工人” 来执行计算机当前无法完成的离散按需任务。它在 Amazon Web Services 下运行,并归亚马逊所有。雇主发布被称为 “人类智力任务” 的工作,例如识别图像或视频中的特定内容,撰写产品说明或回答问题等。
- 《 亚马逊和谷歌正在将新的监视和窃听设备塞进您的居室和汽车里 》
- 《 你知道‘贼’长什么样吗? 》
- 更多内容:“ 关于亚马逊 ”】
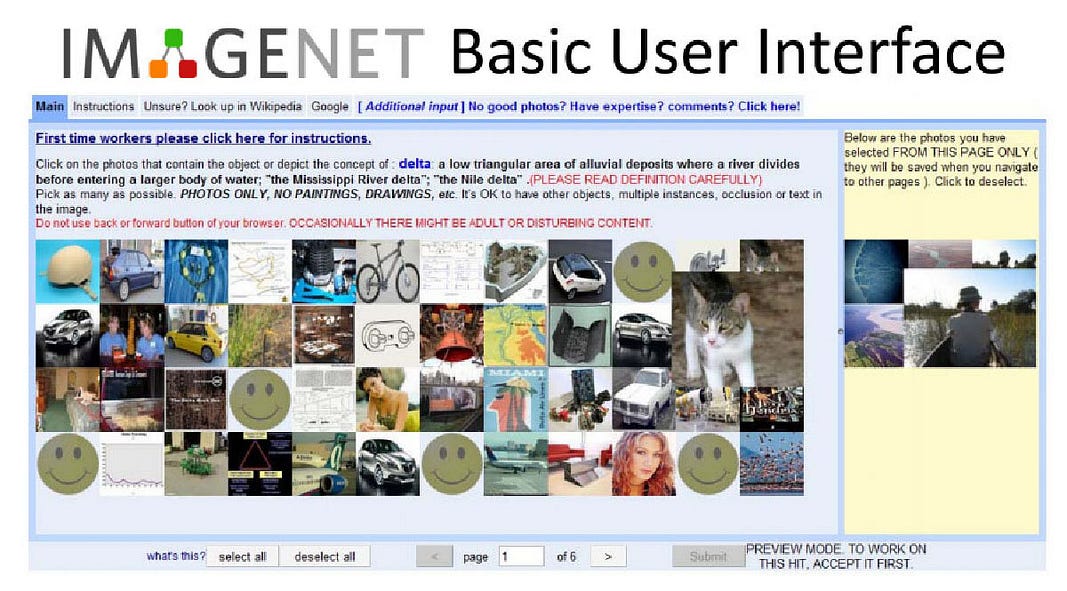
在 ImageNet 的迷宫式结构中导航,就像在博尔赫斯的无限图书馆中漫步那样。它是广阔的,充满了各种奇趣。有苹果、苹果蚜虫、苹果黄油、苹果饺子、苹果天竺葵、苹果果冻、苹果汁、苹果蛆、苹果锈、苹果树、苹果营业额、apple carts(一团糟、捣乱的意思;也是虚拟乐队Gorillaz 一首歌曲的名字)、还有苹果白兰地 等等分类。有热线、热裤、热盘、热锅、热棒、热酱、温泉、热棕榈酒、热浴盆、热气球、热软糖酱和热水瓶的图片。
ImageNet 很快成为了计算机视觉研究的重要资产。它也成为了年度竞赛的基础,世界各地的实验室利用该训练集对比他们的算法,看哪一个能最准确地标记一个图像子集,以努力超越对方。
2012年,来自多伦多大学的一个团队使用卷积神经网络,手到擒来地赢得了最高奖项,为这项技术带来了新的关注。
【注:卷积神经网络是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。 卷积神经网络由一个或多个卷积层和顶端的全连通层组成,同时也包括关联权重和池化层。这一结构使得卷积神经网络能够利用输入数据的二维结构。】
那一刻被广泛认为是当代人工智能发展的一个转折点。ImageNet 比赛的最后一年是2017年,在有限的子集中对物体进行分类的准确率已经从71.8%上升到 97.3%。该子集不包括 “人” 类,原因很快就会显现出来。

分类法
ImageNet 的底层结构是基于 WordNet 的语义结构,WordNet 是普林斯顿大学在20世纪80年代开发的单词分类数据库。该分类法是按照认知同义词集合 “synset” 的嵌套结构组织的。
每一个 “synset” 代表一个不同的概念,同义词归为一组(例如,“auto” 和 “car” 被视为属于同一个 synset)。
然后,这些 synsets 被组织成一个嵌套的层次结构,从一般概念到更具体的概念。例如,“椅子” 这个概念被嵌套为人工制品>陈设>家具>座椅>椅子。这种分类系统大致类似于图书馆用来将书籍排列成越来越具体的类别的那种系统。
WordNet 试图组织整个英语语言,而 ImageNet 则仅限于名词(其理念是名词是可以用来说明图像的东西)。在 ImageNet 的层次结构中,每个概念都被组织在九个顶层类别中的一个里:植物、地质构造、自然物体、运动、人工制品、菌类、人、动物和杂项。在这些类别下面是附加嵌套类的层级。
正如信息科学和科学技术研究领域早已表明的那样, 所有的分类法或分类系统都是政治性的。
例如,在 ImageNet 中(它继承自WordNet),“人体” 类属于自然物>身体>人体这一分支。其子类包括 “男性身体”、“人”、“少年身体”、“成人身体”、“女性身体”。
其中 “成人身体” 类包含 “成年女性身体” 和 “成年男性身体” 两个子类。
我们发现这里有一个隐含的假设: 只有 “男性身体” 和 “女性身体” 才被认为是 “自然的” 。有一个 ImageNet 类别,用于 “Hermaphrodite” 一词,它诡异地(而且令人反感地)位于 Person > Sensualist > Bisexual >分支内,与 “Pseudohermaphrodite” 和 “Switch Hitter” 类别并列。
ImageNet 的分类层次让人想起了美国国会图书馆历史上对LGBTQ主题书籍的分类,归入 “异常性关系,包括性犯罪” 类别 ,美国图书馆协会的同性恋解放特别工作组经过持续数年的运动才终于在1972年说服国会图书馆改变了这一分类。
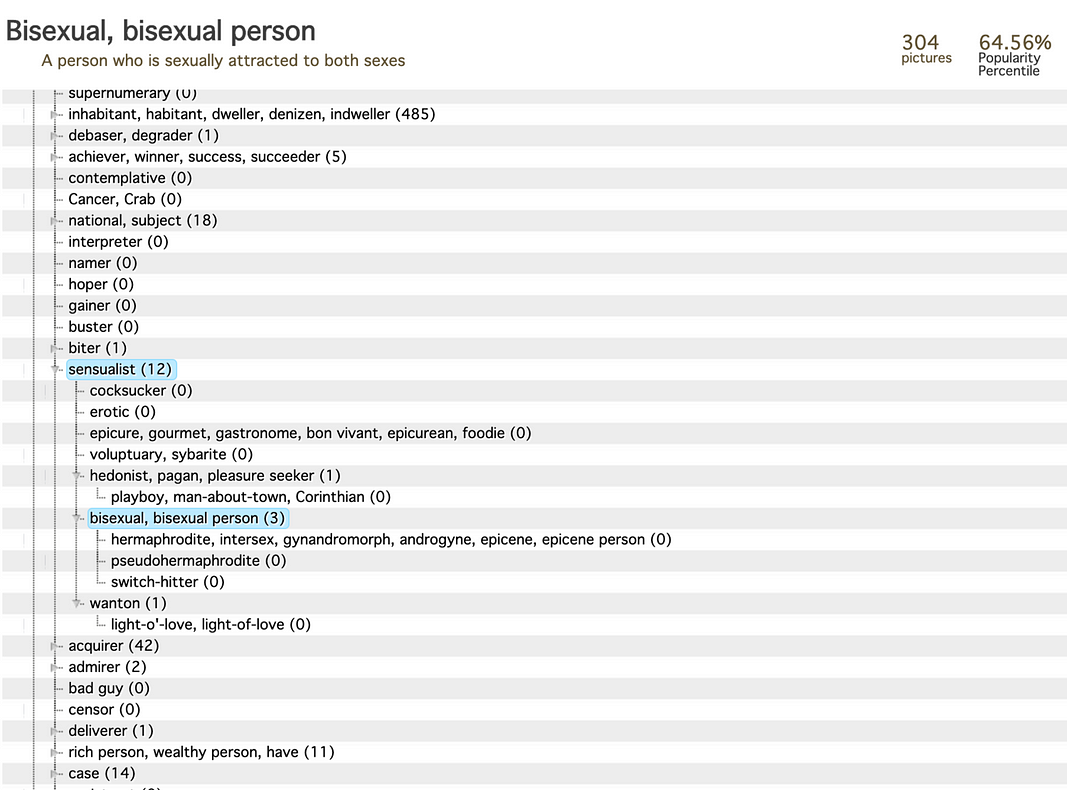
如果从分类学下移到 ImageNet 层次结构中的 21,841 个类别,您就会看到另一种政治形式的出现。
分类类目
在创造分类类目时有一种近乎巫术的东西。创造一个类别或给事物命名,就是把一个几乎无限复杂的宇宙划分为单独的现象。把秩序无差别地强加给物质,把任何现象归于一个类别 —— 也就是给一个事物命名 —— 反过来又是重新证明该类别存在的一种手段。
在 ImageNet 的案例中,“苹果” 或 “苹果黄油” 这样的名词类别看起来似乎合理无争议,但并非所有的名词都是如此。借用语言学家 George Lakoff 的观点:“苹果” 的概念比 “光” 的概念更具有名词性,而 “光” 又比 “健康” 等概念更具有名词性。
名词在一条轴线上占据着不同的位置,从具体到抽象,从描述性到判断性。这些梯度在 ImageNet 的逻辑中被完全抹去了。所有的东西都被扁平化了,并被贴上了标签,就像陈列柜里的蝴蝶标本一样。其结果很可能是有问题的、不合逻辑的、残酷的,尤其是当涉及到应用到人的标签时 。
ImageNet 在顶级类别 “人” 下面有 2,833 个子类别。相关图片最多的子类别是 “妞儿”(有 1,664 张图片),其次是 “祖父”(1,662张)、“爸爸”(1,643张)和首席执行官(1,614张)。
通过这些分类您已经可以开始看到世界观的轮廓。
ImageNet 将人分为大量的类型,包括种族、国籍、职业、经济地位、行为、性格,甚至道德。
种族和民族身份也有分类,包括阿拉斯加土著人、英美人、黑人、非洲黑人、黑人妇女、中美洲人、欧亚人、德裔美国人、日本人、萨米人、拉丁美洲人、墨西哥裔美国人、尼加拉瓜人、尼日尔人、巴基斯坦人、巴布亚人、南美印第安人、西班牙裔美国人、德克萨斯人、乌兹别克人、白人、也门人和祖鲁人。
其他的人则是根据他们的职业或爱好来贴标签的:有童子军、啦啦队队员、认知神经学家、理发师、情报分析师、神学家、零售商、退休人员等等。
随着进一步深入 ImageNet 的人物分类,你会发现, 其中的 “人” 分类发生了急转直下的黑暗变化:
有坏人、应召女郎、吸毒者、深柜男(就是没有出柜的同性恋男子)、罪犯、疯子、过气网红、失败者、笨蛋、伪君子、无耻荡妇、偷窥狂、废柴、闷瓜儿、甩货、性变态、嘚瑟逼、精神分裂症、二流货、老处女、婊子、渣男、傻逼、小白、滥交狂、选择困难症、弱鸡 …… 等类别。有许多种族主义的污言秽语和厌女症的词汇。
以下是 ImageNet 中 “人” 这个类目中的选择:
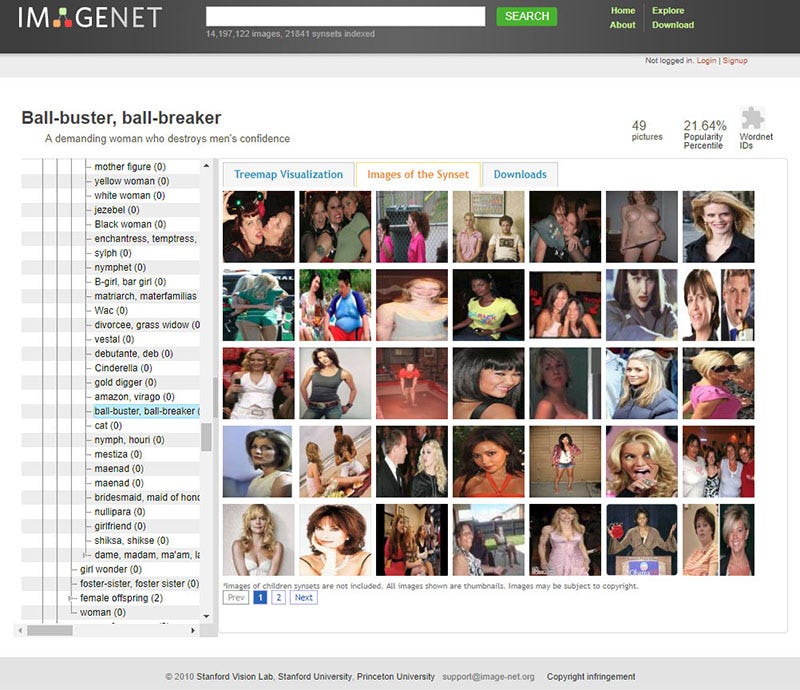
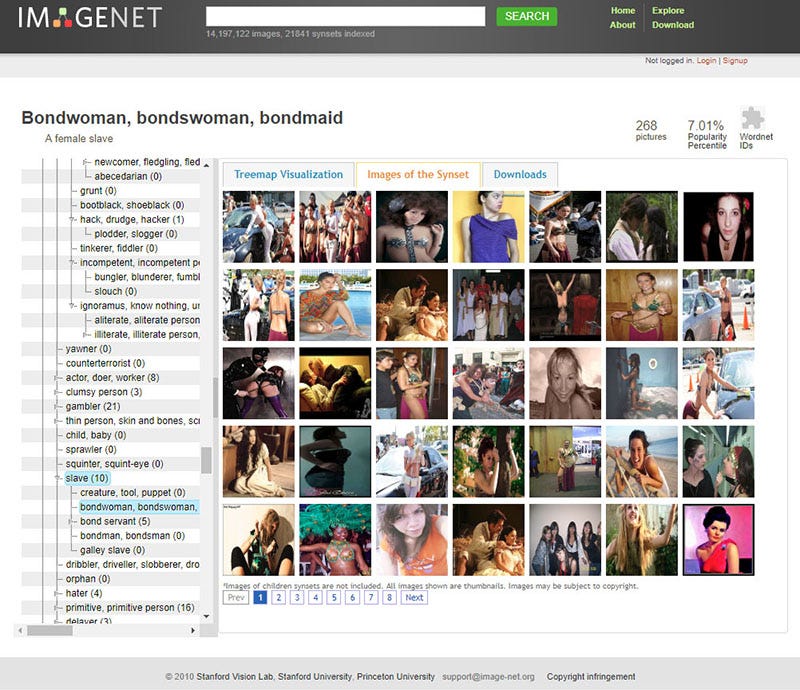
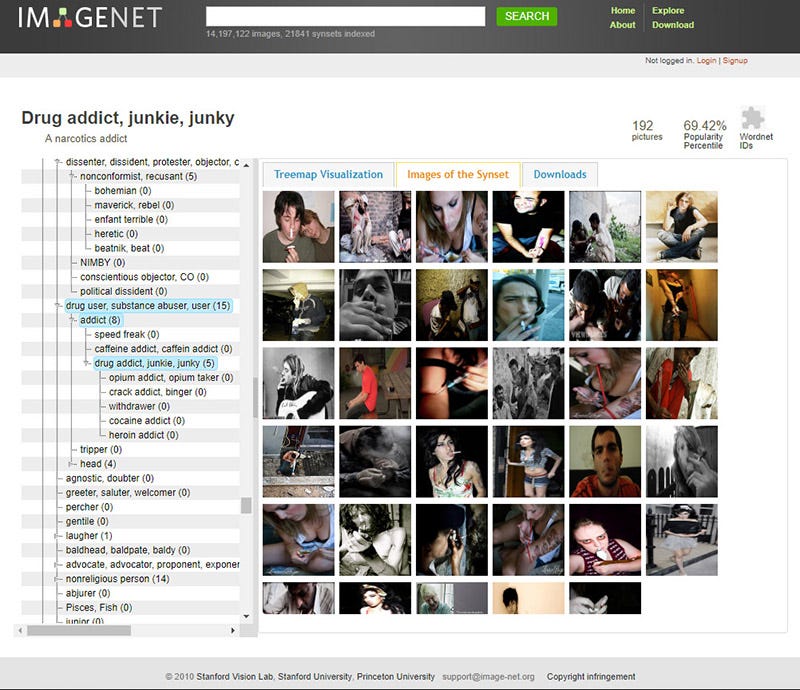
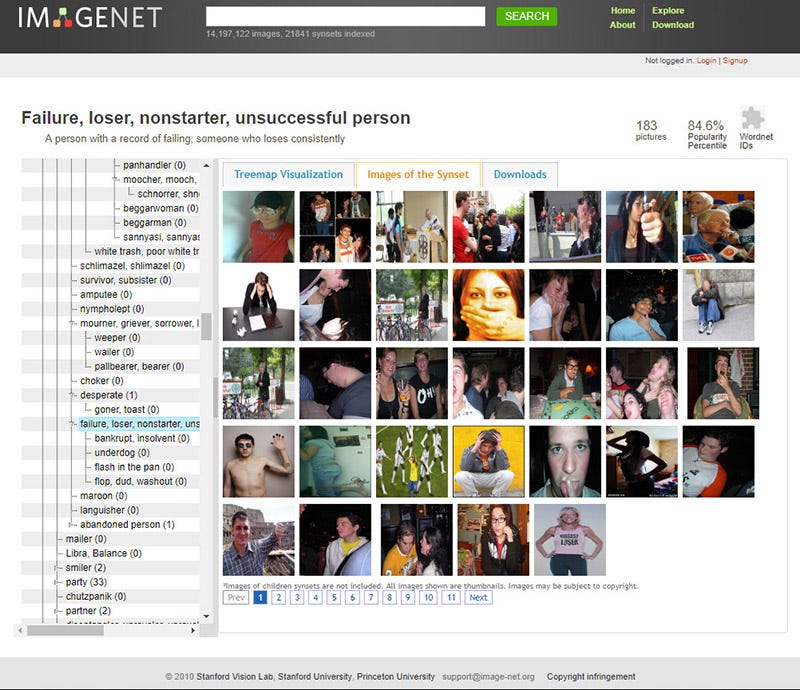
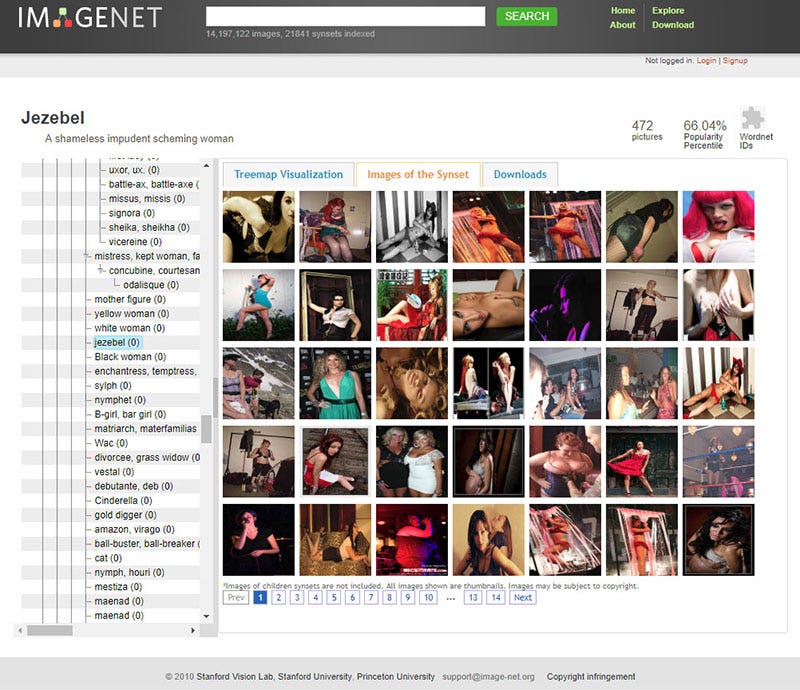
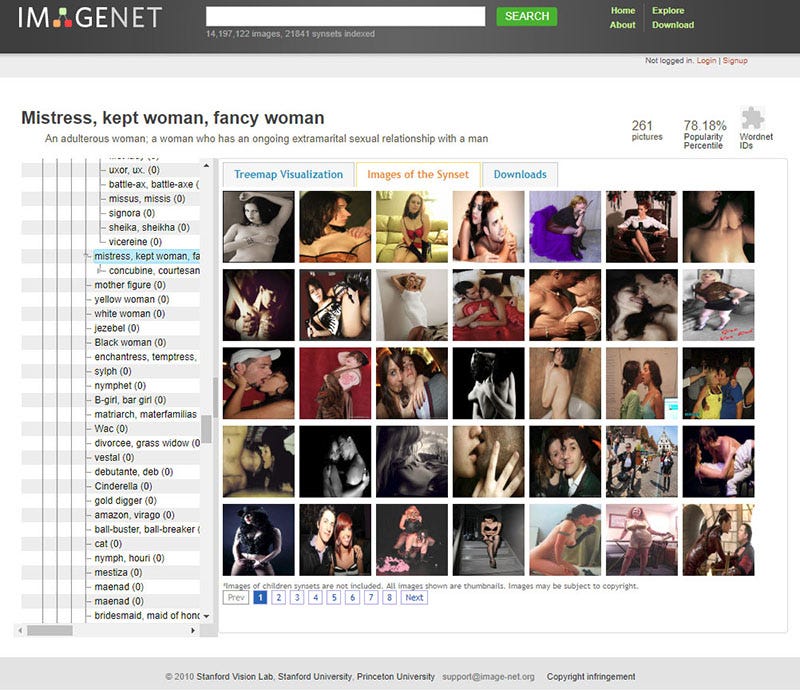
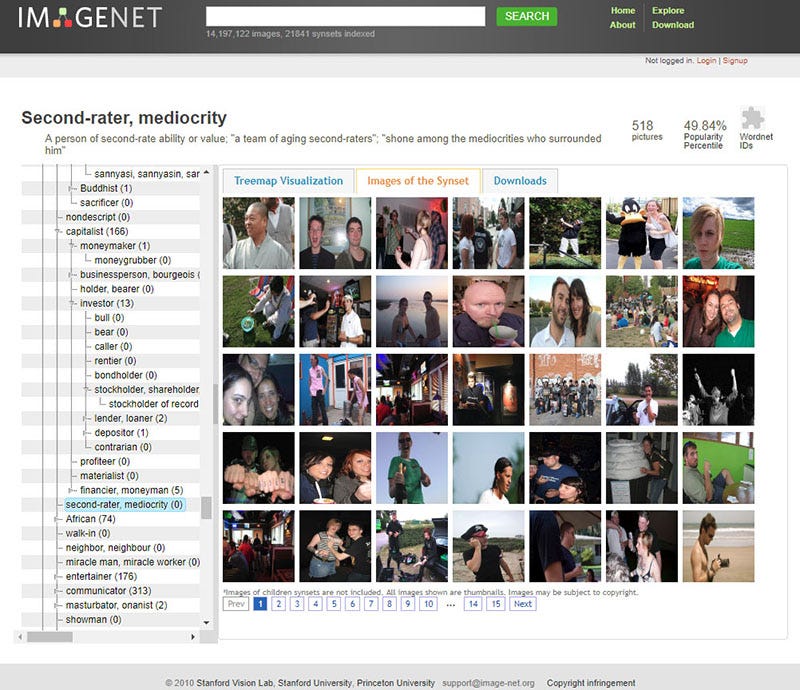
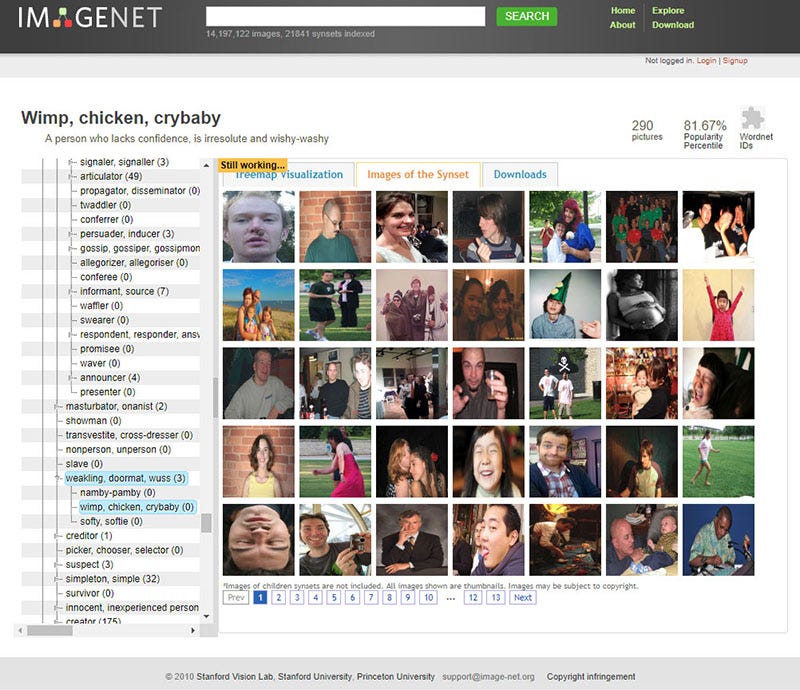
当然,ImageNet 通常用于对象识别 —— 因此,“人” 类别很少在技术会议上被讨论,也没有得到公众的关注。
然而, 这个由真人图像组成的复杂架构,加上常常是攻击性的标签,已经在互联网上公开十年多了。它提供了一个强大而重要的例子 —— 说明人类分类的复杂性和危险性 ,以及在 “小号手” 或 “网球运动员” 等本应没有问题的标签与 “笨蛋”、“黑白混血(辱骂性的词汇)” 或 “乡下土鳖” 等概念之间的交叉谱系。
无论任何特定类别的所谓中立性,图像的选择都会以性别化、种族化、能力主义、和年龄歧视的方式歪曲其意义。
ImageNet 是一个对象课,如果你愿意的话,可以研究一下当人们被像对象一样分类时会发生什么。而这种做法在近几年才越来越普遍, 往往是在大的人工智能公司内部,外人没有办法看到图像是如何被排序和分类的。
最后,就是 ImageNet 的 “人” 类目的数千张图片从何而来的问题。
ImageNet 的创建者从谷歌等图片搜索引擎中大量采集图片,在人们不知情的情况下盗用了他们上传到互联网的自拍和度假照片,然后将其贴上标签并重新包装,作为整个领域的基础数据。
当您审视被贴上标签的图片的基础层时,就会发现非常值得怀疑的符号学假设、19世纪人文学科的回声,以及在没有得到人们同意或参与的情况下对其进行分类的突出伤害。
ImageNet Roulette:分类实验
ImageNet 数据集通常用于对象识别。但作为我们的考古方法的一部分,我们有兴趣看看如果我们专门在其 “人” 的类别上训练一个AI模型会发生什么。这个实验的结果就是 ImageNet Roulette。
【注:“ImageNet Roulette” 是一个由程序员 Leif Ryge,纽约大学教授、AI Now研究所共同创始人 Kate Crawford,以及艺术家 Trevor Paglen 最近为一个名为 “训练人类” (Training Humans) 的艺术展创建的网站。只需上传一张人像照片,该工具会运行一些常见的机器学习软件,然后返回决定适用于你的标签。】
ImageNet Roulette 使用一个开源的 Caffe 深度学习框架(在加州大学伯克利分校制作),对 “人” 这个类别中的图像和标签进行训练(目前 “停机维护”)。专有名词被删除。
当用户上传图片时,该应用程序首先运行人脸检测器来定位任何人脸。如果发现任何人脸,它就会将其发送到 Caffe 以进行分类。然后,应用会返回原始图像,并以一个边界框显示检测到的人脸和分类器分配给图像的标签。如果没有检测到人脸,该应用将整个场景发送到 Caffe,并返回左上角带有标签的图像。
正如我们所展示的,ImageNet 包含了许多有问题的、令人反感的和奇怪的类别。因此,ImageNet Roulette 所返回的结果往往借鉴了这些类别。
这是设计上的:我们希望阐明 当技术系统使用有问题的训练数据集进行训练时会发生什么 。 AI对人的分类很少让被分类的人看到。ImageNet Roulette 提供了一个窥视这一过程的机会 —— 并展示了事情是如何出错的。
https://imagenet-roulette.paglen.com/
标记图像
图像充满了潜在的意义、无法解决的问题和矛盾。为了解决这些含糊不清的问题,ImageNet 的标签常常将图像压缩和简化为死板的平庸。一张照片上,一个皮肤黝黑的幼儿穿着破烂肮脏的衣服,抱着一个沾满灰土的娃娃。孩子的嘴是张开的。这张照片完全没有背景。这个孩子是谁?他们在哪里?照片上只是简单地标注了 “玩具”。
但有些标签就是无厘头。一个女人在飞机座椅上打瞌睡,右臂保护性地蜷缩在怀孕的肚子上。这张图片被贴上了 “势利眼/虚荣” 的标签。一张经过PS的图片显示,笑容可掬的奥巴马身穿纳粹制服,手臂高举,手持纳粹旗。它被贴上了 “布尔什维克” 的标签。
以下是带标签的图像,被 ImageNet 的作者编辑的面孔:



在训练集的图像层,像其他地方一样,我们发现了假设、政治和世界观。
例如,根据 ImageNet,电影演员 Sigourney Weaver 被标记为一个 “两性人”,一个戴着草帽的年轻人被标记为 “笨蛋”,一个躺在沙滩巾上的年轻女人被标记为 “盗窃惯犯”。但 ImageNet 的世界观并不限于图片和标签的怪异或贬义的连缀。
其他关于图片和概念之间关系的假设让人想起了相面算卦,即 通过观察一个人的身体和脸部特征就断定其基本特征的 伪科学假设 。
ImageNet 将这一点发挥到了极致, 它假定一个人是 “债主”、”势利眼”、“游手好闲” 、或者 “奴才” …… 都可以通过察看其照片来判断 。
在 ImageNet 奇怪的形而上学中,“助理教授” 和 “副教授” 有单独的图像类别 —— 就好像如果某人获得晋升,他们的长相就能反映出等级变化似的 …
当然,这些假设都有其自己的黑暗历史和相关的政治背景。
UTK:根据您的面孔给您贴上种族和性别标签
1839年,数学家 François Arago 声称,通过照片,“物体在数学上保存了它们的形态。”
在19世纪帝国主义和社会达尔文主义的背景下,摄影帮助活跃了各种形式的颅相学、生理学和优生学,并给它们披上了 “科学” 的虚假外衣。
Francis Galton 和 Cesare Lombroso 等生理学家创造了罪犯的合成图像, 研究了妓女的脚,测量了头骨,并编制了细致的标签图像和测量档案,所有这些都是为了利用机械性过程来检测种族、犯罪和偏离资产阶级理想的分类中的视觉信号。
这样做的目的是为了捕捉和病理化被视为 “离经叛道” 或 “犯罪” 行为的东西,并使这种行为在世界上可以观察到。
而正如我们将要看到的,不仅生理学的基本假设在当代训练集上得到了回归,而且,事实上, 一些训练集的设计本身就是将算法和面部特征这些古老的卡尺来进行现代版的颅骨测量 。
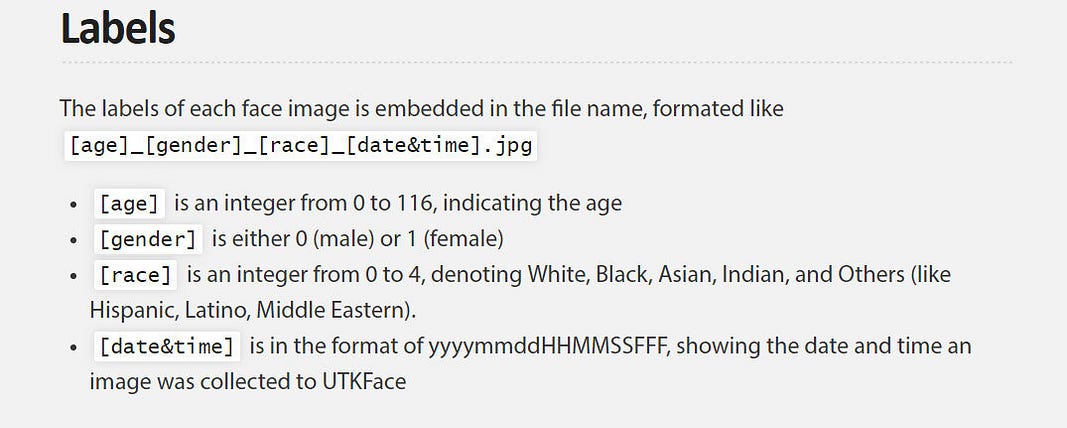
例如,UTKFace 数据集(由田纳西大学诺克斯维尔分校的一个小组制作)由超过2万张带有年龄、性别和种族注释的人脸图像组成。该数据集的作者表示,该数据集可用于各种任务,如自动人脸检测、年龄估计和年龄累计。
以下是UTKFace数据集:



每张图片的注释包括每个人的估计年龄,以年数表示,从0到116。 性别是一个二元选择 :男性为0或女性为1;其次,种族是从0到4的分类,并将人们归入五个等级之一:白人、黑人、亚裔、印第安人或 “其他人”。
这里的政治因素既明显又令人不安 。在类别层面,研究者对性别的概念是一个简单的二元论,“男性” 和 “女性” 是唯一的选择。在图像标签的层面上,它在假设一个人的性别身份可以通过照片来确定。
其种族分类模式更使人想起二十世纪许多有严重问题的种族分类。例如,南非种族隔离制度试图将整个人口分为四类:黑人、白人、有色人种或印第安人。
大约在1970年,南非政府建立了一个统一的 “身份名册”,被称为 “Book of Life”, 它与IBM建立的一个集中化管理的数据库相连 。这些分类依据的是 “外表、普遍接受程度、或声誉” 等可疑的和显然是不断变化的标准,许多人被重新分类,有时是多次被分类。
南非的种族分类制度与美国的 “一滴血” 规则还不同,美国的 “一滴血” 规则指出,即使有一个非洲裔祖先,此人也会使某人被定位为黑人,这可能是因为几乎所有南非白人都有一些可追溯的非洲黑人祖先。不论此人的皮肤是什么颜色。
最重要的是,这些分类制度对人们造成了巨大的伤害,而难以捉摸的纯 “种族” 标志的分类方法始终存在争议。然而,寻求通过生产 “更多样化” 的人工智能训练集来改善问题,却带来了自身的复杂性。

IBM的多元化人脸
IBM的 “Diversity in Faces” 数据集的创建是为了回应批评者,这些批评者指出,该公司的面部识别软件往往根本无法识别皮肤较黑的人的面孔。
IBM公开承诺改进他们的面部识别数据集,使其更具 “代表性”,并因此发布了 “Diversity in Faces”(DiF)数据集。
DiF 被构建为 “确保人脸识别公平性和准确性的计算实践基础”,它由从Yahoo Flickr Creative Commons 数据集中提取的近百万张人物图像组成,专门为实现肤色、面部结构、年龄和性别等类别之间的统计均等而组装。
该数据集本身延续了收集数十万张不怀好意的人上传到 Flickr 等网站的图片的做法,但该数据集包含了一组独特的分类,这在之前的其他人脸图像数据集中是没有的。
IBM DiF 团队询问年龄、性别和肤色是否真的足以生成一个能够确保公平性和准确性的数据集,并得出结论称:需要更多的分类。
于是他们进入了真正奇怪的领域:包括用面部对称性和头骨形状来构建一个完整的面部图像 。
研究人员声称,使用颅面特征是合理的,因为它能捕捉到一个人的面部信息,比单纯的性别、年龄和肤色要精细得多。数据集所附的论文特别强调了之前所做的工作,表明肤色本身就是一个弱的种族预测因子,但是,这就引出了一个问题,即 为什么转向颅骨形状是合适的。
所谓的颅骨测量学是十九世纪生物决定论的一种主要方法。正如 Stephen Jay Gould 在其《The Mismeasure of Man》一书中所表明的那样, 十九世纪和二十世纪的伪科学家利用头骨大小作为一种虚假的方法,宣称 “白人天生优于黑人”,而且宣称不同的头骨形状和重量决定了人们的智商 — — 始终是按种族划分的。
虽然公司为建立更多样化的培训集所做的努力经常被冠以 “增加公平性” 和 “减少偏见” 的 幌子 ,但很明显, 企业有强烈的商业需求来生产能在更广泛的市场上更有效地发挥作用的工具。
然而,在这里,对人进行分类和分级的技术过程也完全是一种政治行为。例如,如何在数据集中实现 “公平” 分配?
IBM 决定使用数学方法来量化 “多样性” 和 “均匀性”,这样在整个数据集中,每一个被量化的特征都存在一个一致的均匀性衡量标准。
数据集还包含了年龄和性别的主观注释,这些注释是使用三个独立的 Amazon Turk 工人为每张图片生成的,类似于 ImageNet 所使用的方法 —— 所以人们的性别和年龄是根据三个点击工人对从互联网上搜刮的照片所显示的内容的猜测来 “预测” 的 。这让人想起了早期的狂欢游戏 “猜猜你的体重!”,这俩东西具有类似的 “科学性”。

归根结底,除了这些深层次的方法论问题外,多样性的概念和政治历史的意义正在被剥夺,而仅仅取代为扩大的生物表型。
在这种情况下,多样性只是意味着更广泛的头骨形状和面部对称性。对于计算机视觉研究者来说,这似乎是一种 “公平的数学化”,要知道 它只是为了提高监控系统的效率。
而即使在尝试了这么多扩大人的分类方式之后,Diversity in Faces 集仍然依赖于性别的二元分类:人们只能被贴上男性或女性的标签。 实现不同类别之间的均等并不等于实现多样性或公平性,IBM 的数据构建和分析在狭隘的世界观中延续了一套有害的分类方式 。
训练集的认识论
视觉AI系统的基础假设是什么?
首先,训练集的基础理论范式假设概念 —— 无论是 “玉米”、“性别”、“情感” 还是 “屌丝” —— 首先是存在的,而且这些概念是固定的、普遍的,具有某种超越性的基础和内在一致性。
其次,它假定图像与概念、表象与本质之间存在着固定的、普遍的对应关系。更重要的是,它假定图像、参照物和标签之间存在着不复杂的、不言自明的、可测量的联系。
换句话说,它假设不同的概念 —— 无论是 “玉米” 还是 “窃盗癖” —— 都有某种本质将它们的每一个实例联系在一起,而这种潜在的本质 “可以”在视觉上表现出来。
此外,该理论认为,通过使用统计学方法在一系列被标记的图像中寻找形式特征,这种视觉本质是可以辨别出来的。 该理论认为,比如 被称为 “失败者” 的人的图像包含某种视觉模式,可以将他们与 “农民”、“助理教授” 、或苹果等区别开来。
最后,这种方法假设所有具体的名词都是平等地被创造出来的,许多抽象的名词也在具体的和视觉层面上表达自己(如 “幸福” 或 “反犹主义”)。
“反犹主义” 长什么样?
当代计算机视觉和人工智能中无处不在的标签图像的训练集是建立在对图像、标签、分类和表征的性质的未经证实和不稳定的认识论和形而上学假设的基础上的。此外, 这些认识论和形而上学的假设可以追溯到历史上对人进行视觉评估和分类的方法,作为压迫和种族排斥的工具 。
数据集并不是简单的喂养算法的原材料,而是政治干预 。因此,围绕人工智能系统中所谓 “偏见” 的许多讨论都错过了真正的议题:并不存在什么 “中立”、“自然” 或 “非政治” 的改良。不存在简单的技术 “修复”。 收集图像、对它们进行分类和贴标签的整个工作本身就是一种政治形式,充满了关于谁能决定图像的含义以及这些表征所执行的社会和政治工作的高度敏感问题。
失踪的 “人”
2019年1月,ImageNet 的 “人” 类别中的图片开始消失。突然间,斯坦福大学的服务器上再也无法访问120万张照片。啦啦队员、潜水员、电焊工、辅祭男童、退休人员和飞行员的照片都消失了。一个喝啤酒的男人被定性为 “酒鬼” 的照片消失了,一个穿比基尼的女人被称为 “婊子” 的照片和一个被归类为 “loser” 的小男孩的照片也消失了。一个男人吃三明治的照片(被贴上 “贪婪的人” 的标签)也遭遇了同样的命运。
当你搜索这些图片时,ImageNet 网站的回应是,它正在维护中,只有 ImageNet 比赛中使用的类别仍然包含在搜索结果里。
但重新上线后,网站上的搜索功能就被修改了,只能返回已被纳入 ImageNet 年度计算机视觉竞赛的类别的结果。截至本文撰写时,“人” 类别仍可从数据集的在线界面浏览,但图像无法加载。原始图像的URL仍然可以下载。
在接下来的几个月里,其他用于计算机视觉和人工智能研究的图像库也开始消失。作为对 Adam Harvey 和 Jules LaPlace 发表的研究的回应,杜克大学下架了一个大规模监视学生上课的监控摄像头镜头照片库(称为 Multi-Target, Multi-Camera [MTMC] 数据集)。
结果发现,该数据集的作者违反了机构审查委员会批准的条款,他们在公共空间收集人们的图像,并将其数据集公开。
由监控录像创建的类似数据集从科罗拉多大学科罗拉多斯普林斯的服务器上消失了,更多的是斯坦福大学,从安装在旧金山标志性的 BrainWash 咖啡馆的网络摄像头中提取的人脸集合 “应当事人的要求被删除访问”。
到了6月初,微软也紧随其后,删除了他们具有里程碑意义的 “MS-CELEB” 收集的约1000万张照片, 这些照片来自2016年从互联网上搜罗的10万人 。这是世界上最大的公共面部识别数据集, 被收录其中的人不仅有著名演员和政治家,还有记者、活动家、政策制定者、学者和艺术家等 。
具有讽刺意味的是,在未经任何同意的情况下被纳入该集的多个人都是以批判监控和面部识别本身的作品而闻名的,包括电影制片人《第四公民》的导演劳拉·波特拉斯(Laura Poitras)、数字权利活动家吉利安·约克(Jillian York)、批评家叶夫根尼·莫罗佐夫(Evgeny Morozov)和《 监视资本主义 》(Surveillance Capitalism)的作者肖沙娜·祖博夫(Shoshana Zuboff)。
在《金融时报》根据 Harvey 和 LaPlace 的调查发表后,这套东西就消失了。微软的发言人仅仅声称,它被删除 “是因为研究挑战已经结束”。

一方面,从互联网上删除这些有问题的数据集似乎是一种胜利。通过让它们不再被访问,解决了最明显的侵犯隐私和道德问题。但是,将它们下线并没有停止它们在全世界的工作:这些训练集已经被下载了无数次,并且已经进入了许多生产型人工智能系统和学术论文中。
将它们完全删除,不仅会失去人工智能历史的重要部分,而且研究人员也无法看到假设、标签和分类方法是如何在新系统中被复制的,或者追踪工作系统中表现出的倾向性和偏见的来源。
面部识别和情感识别人工智能系统已经在向招聘、教育和医疗保健领域传播。它们是机场安检和《财富》500强公司面试协议的一部分。无法看到人工智能系统的训练基础,就失去了了解它们如何工作的重要取证方法。这具有严重的后果 。
例如,最近剑桥大学一名博士生领导的一篇论文介绍了一种实时无人机监控系统,以识别公共区域的 “暴力分子”。它在 “暴力行为” 的数据集上进行训练,并将这些模型用于无人机监控系统,以检测和隔离人群中的暴力行为。
该团队创建了个体暴力行为(AVI)数据集,该数据集由2000张图像组成,这些图像中的人参与了五种活动:拳打、刺杀、射击、脚踢和扼杀。为了训练他们的人工智能,他们要求25名年龄在18到25岁之间的志愿者 **模仿** 这些动作。
看视频几乎是滑稽的。演员们站得很远,做出奇怪夸张的手势。这看起来就像儿童表演的哑剧,或者是建模失败的游戏角色。 完整的数据集不供公众下载。
首席研究员 Amarjot Singh (现就职于斯坦福大学)表示, 他计划通过在两个重大节日的上空飞行无人机来测试人工智能系统,并有可能在印度的国家边境进行测试。
对AVI数据集的考古分析 —— 类似于我们对 ImageNet、JAFFE 和 Diversity in Faces 的分析 —— 可能会有很大的启示。 舞台上的暴力表演和现实世界的案例之间显然存在着显著的差异。研究人员正在训练无人机识别暴力的默剧,以及所有可能带来的误解。
此外,AVI数据集没有任何关于 “不是暴力但可能看起来像暴力的行为” 的内容;他们也没有公布任何关于他们的假阳性率(他们的系统将非暴力行为检测为暴力的频率)的细节。 在他们的数据公布之前, 无法 对他们如何对人体、行动或不行动进行的分类和解释进行取证测试。
【注: 关于该数据集的中文内容非常之多,想想看,这意味着什么? 】
这就是无法访问或消失的数据集的问题。 如果这些数据集正在或曾经被用于在日常生活中发挥作用的系统中,就必须能够研究和理解它们所规范的世界观。 制定框架,使未来的研究人员能够以不造成伤害的方式访问这些数据集,是一个需要进一步努力的课题。

结论:谁来决定?
二十世纪初的 Lombrosian 犯罪学家和其他语言学家并没有把自己看作是政治反动派。相反,正如 Steven Jay Gould 所指出的那样,他们往往是自由主义者和社会主义者,他们的意图是 “利用现代科学作为一把清洁的扫帚,从法学中扫除自由意志和不可减轻的道德责任等过时的哲学包袱”。
他们认为,他们研究犯罪行为的人体测量可以导致一种更开明的司法适用方法。他们中的一些人真正相信自己正在 “消除” 刑事司法系统的偏见,通过应用他们的 “科学” 和 “客观” 方法创造 “更公平” 的结果。
在颅相学和 “犯罪人类学” 这类伪科学的鼎盛时期,艺术家 René Magritte 完成了一幅烟斗画,并配上了 “Ceci n’est pas une pipe” 的字样(“这不是烟斗”)。
Magritte 将这幅画称为 La trahison des images,”图像的背叛”。同年,他在超现实主义通讯 La Révolution surréaliste 上写了一篇文章。“Les mots et les images” 是对图像、标签、图标和参照物的复杂性和微妙性的戏弄, 强调了图像与文字或语言概念之间的关系在多大程度上是很不简单的。
该系列作品将在一系列绘画作品中达到高潮,如前述;“这不是一个苹果。”
Magritte 和生理学家的表现方法之间的对比,说明了对图像及其标签之间的基本关系以及对表现本身的两种截然不同的概念。对生理解剖学家来说,有一种潜在的信念,即 一个人的形象和这个人的性格之间的关系是刻在图像本身上的。
Magritte 的假设几乎是截然相反的:图像本身与似乎所代表的事物之间充其量只有一种非常不稳定的关系,这种关系可以被任何有权力说清某幅图像的含义的人加以雕琢 。对 Magritte 来说,图像的意义是关系性的,是可以争论的。
乍一看,Magritte 的画作似乎只是一个简单的符号学噱头,但是,Magritte 在画作中所强调的潜在动态却指向了更广泛的表征和自我表征的政治。

争取正义的斗争在一定程度上一直是对图像和代表意义的斗争 。1968年,非裔美国环卫工人举行罢工,抗议危险的工作条件和孟菲斯种族主义政府的可怕待遇。他们举起的牌子是在回忆19世纪的废奴运动的著名口号:“I AM A MAN” ;1970年代,同性恋解放运动人士使用了最初在纳粹集中营中被使用的符号,以识别被标记为同性恋、双性恋和变性者的囚犯。粉红色的三角形成为了骄傲的徽章,是同性恋解放运动最具标志性的符号之一。
诸如此类的例子 — — 人们试图定义自己所代表的意义的案例 — — 在争取正义的斗争中随处可见。 代表性并不简单地局限于语言和文化领域,而是在权利、自由和自决形式方面具有重要的实际意义 。
在人工智能中使用的训练集的架构和内容有很多利害关系。它们可以促进平等或加强歧视,批准或拒绝,使可见或不可见,判断或执行。因此,我们需要研究它们 —— 因为它们已经被用来研究我们了,并且需要对它们的后果进行更广泛的公开讨论,而不是将其保留在学术走廊内。
随着这些训练集越来越成为城市、法律、后勤和商业基础设施的重要部分,它们有一个重要的但一直未被充分研究的角色,即:以它们自己的图像塑造世界的巨大权力。⚪️
📌 以下是本文中涉及的一些相关书目和论文推荐,以帮助您理解这篇文章中的内容 —— 下面所有内容均可在此下载 : https://www.patreon.com/posts/wa-jue-ai-ji-qi-43038761
1、Meredith Broussard, Artificial Unintelligence: How Computers Misunderstand the World (Cambridge, Massachusetts, and London: MIT Press, 2018)
2、Daniel Crevier, AI: The Tumultuous History of the Search for Artificial Intelligence (New York: Basic Books, 1993)
3、Stuart J. Russell and Peter Norvig, Artificial Intelligence: A Modern Approach, 3rd ed, Prentice Hall Series in Artificial Intelligence (Upper Saddle River, NJ: Prentice Hall, 2010)
4、W. J. T. Mitchell, Picture Theory: Essays on Verbal and Visual Representation, Paperback ed., [Nachdr.] (Chicago: University of Chicago Press, 2007).
5、Lisa Feldman Barrett et al., “Emotional Expressions Reconsidered: Challenges to Inferring Emotion From Human Facial Movements,” Psychological Science in the Public Interest 20, no. 1 (July 17, 2019)
6、Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton, “ImageNet Classification with Deep Convolutional Neural Networks,” in Advances in Neural Information Processing Systems 25, ed. F. Pereira et al. (Curran Associates, Inc., 2012)
7、Anja Bechmann and Geoffrey C. Bowker, “Unsupervised by Any Other Name: Hidden Layers of Knowledge Production in Artificial Intelligence on Social Media,” Big Data & Society 6, no. 1 (January 2019)
8、Joy Buolamwini and Timnit Gebru, “Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification,” in Conference on Fairness, Accountability, and Transparency, 2018
9、Gould, The Mismeasure of Man
10、视频:Amarjot Singh, Eye in the Sky: Real-Time Drone Surveillance System (DSS) for Violent Individuals Identification, 2018,
11、还有一个概述式的论文,主张思考方式,也是很好的: More than a few bad apps
文章版权归原作者所有。
